In this chapter, I will be more explicit about the underlying ideas you have encountered in the previous chapter. In particular:
We will be studying a classic empirical application very closely. This is the Solow growth model.
This empirical application exposes you to topics such as the inclusion of more \(X\)’s, transformations of variables, the need for uncertainty quantification, and, most importantly, the origins of an assumed form of a model. All of these require further investigation and exposition.
2.1 Motivating example: Solow growth model
As Bernanke and Gürkaynak (2002) state, Mankiw, Romer, and Weil (1992) “begins one of the most influential and widely cited pieces in the empirical growth literature”. This paper, henceforth MRW, tests a particular economic theory, finds that the data are incompatible with the theory, and then makes adjustments to the theory.1 Their main research questions were about:
whether or not the predictions of the “textbook” Solow growth model are compatible with the data
whether poor countries are able to catch up to rich countries
2.1.1 The theoretical framework
The “textbook” Solow growth model imposes the following assumptions:
Rates of saving \(s\), population growth \(n\), growth in technological progress \(g\), and rate of depreciation \(\delta\) are exogenous and constant.
One output \(Y\left(t\right)\); two inputs, capital \(K\left(t\right)\) and labor \(L\left(t\right)\): \(t=0\) is the initial starting point. \(L(0)\), \(K(0)\), \(A(0)\), and \(Y(0)\) are the initial levels of labor, capital, technology, and output, respectively.
Cobb Douglas technology with \(\alpha\) constant \(Y\left(t\right)=\left[K\left(t\right)\right]^{\alpha}\left[A\left(t\right)L\left(t\right)\right]^{1-\alpha}\)
Competitive labor and capital markets
Let \(k\left(t\right)\) be the capital per unit of effective labor, i.e., \[k\left(t\right)=K\left(t\right)/\left[A\left(t\right)L\left(t\right)\right].\] Similarly, we can define output per unit of effective labor as \[y\left(t\right)=Y\left(t\right)/\left[A\left(t\right)L\left(t\right)\right].\] The evolution or law of motion of \(k\) is given by \[\dot{k}\left(t\right)=\dfrac{dk\left(t\right)}{dt}=sy\left(t\right)-\left(n+g+\delta\right)k\left(t\right).\]
Let \(t^*\) be the time at which steady state was reached. Steady state is reached when \(\dot{k}=0\). The steady state capital per unit of effective labor \(k(t^*)\) could be obtained from \(\dot{k}=0\) and it is given by \[k(t^{*})=\left(\dfrac{s}{n+g+\delta}\right)^{1/\left(1-\alpha\right)}.\] Since \(\log y\left(t\right)=\alpha\log k\left(t\right)\), we can write the steady state income per unit of effective labor \(y(t^*)\) as \[\log y(t^*) = \alpha\log k\left(t^*\right).\]
A problem with measurements involving effective labor is that they involve technological components, which may be hard to measure. Ultimately, we have to look at measurements in per capita terms. The idea is to look at how per effective labor measurements are related to per capita measurements: \[\begin{eqnarray}\log y(t) &=& \log\frac{Y(t)}{A(t)L(t)}\\
&=& \log \frac{Y(t)}{L(t)}-\log A(t) \\
&=& \log \frac{Y(t)}{L(t)}- \log A(0)-gt
\end{eqnarray} \tag{2.1}\] The previous equation is valid at any point in time, including the steady state. Let \(y^*\) be the steady state income per capita. As a result, we have \[\log y(t^*)=\log y^*-\log A(0)-gt^*.\]
In the steady state, income per capita (\(Y/L\)), rather than income per unit of effective labor will then be given by \[\log y^{*}=\log A\left(0\right)+gt^{*}+\dfrac{\alpha}{1-\alpha}\log s-\dfrac{\alpha}{1-\alpha}\log\left(n+g+\delta\right). \tag{2.2}\]
2.1.2 The econometic framework
We will now start from Equation 2.2 and “convert” it into an econometric model. After that, we ask whether linear regression enables us to answer the research questions posed by MRW.
The theoretical result in Equation 2.2 explicitly quantifies “the impact of saving and population growth on real income”. MRW also state that
Because the model assumes that factors are paid their marginal products, it predicts not only the signs but also the magnitudes of the coefficients on saving and population growth.
The most important assumption is about the initial level of technology \(A(0)\), because this component is either unobservable or extremely difficult to measure. MRW assume that \[\log A\left(0\right)=a+\varepsilon.\] MRW also assume that \(s\) and \(n\) are independent of \(\varepsilon\).2 Finally, \(g\) and \(\delta\) are assumed to be constant across countries. Depreciation rates do not vary greatly across countries.3 Therefore, taking all these assumptions together along with Equation 2.2, we have \[\log y^{*} = a+gt^{*}+\dfrac{\alpha}{1-\alpha}\log s-\dfrac{\alpha}{1-\alpha}\log\left(n+g+\delta\right)+\varepsilon, \tag{2.3}\] where \(\varepsilon\) is independent of \(s\) and \(n\).
How could we make sense of Equation 2.3 in light of what you have seen in Chapter 1? Both predictive and causal elements are present in the language used in the paper. The assumption that \(\varepsilon\) is independent of \(s\) and \(n\) implies that \(\mathsf{Cov}\left(s, \varepsilon\right)=0\) and \(\mathsf{Cov}\left(n, \varepsilon\right)=0\).4 We can conclude that \(\varepsilon\) has the properties of an error from best linear prediction of \(\log\ y^*\) given \(\log\ s\) and \(\log\ (n+g+\delta)\).
Recall that in Chapter 1, I have introduced best linear prediction of some \(Y\) given \(X_1\), where \(X_1\) is a single predictor. Although we have not discussed best linear prediction in the presence of more than one predictor, the idea extends to the more general case and we will explore it further in this chapter.
We can express Equation 2.3 in terms of our notation for a linear regression model, i.e. \[\underbrace{\log\ y^*}_{Y} = \underbrace{a+gt^{*}}_{\beta_0}+\underbrace{\dfrac{\alpha}{1-\alpha}}_{\beta_1}\underbrace{\log s}_{X_1}\underbrace{-\dfrac{\alpha}{1-\alpha}}_{\beta_2}\underbrace{\log\left(n+g+\delta\right)}_{X_2} +\underbrace{\varepsilon}_{U}. \tag{2.4}\] In this case, the component represented by \[a+gt^*+\dfrac{\alpha}{1-\alpha}\log s-\dfrac{\alpha}{1-\alpha}\log\left(n+g+\delta\right)\] becomes the best linear predictor of \(\log\ y^*\) given \(\log\ s\) and \(\log\ (n+g+\delta)\).
Another thing to observe is that MRW make a stronger assumption than what is needed for best linear prediction. Why? The answer to that question rests on the transformations of the original variables. For example, we need the logarithm of the savings rate rather the actual savings rate. How will the presence of these transformed variables affect what we have learned in Chapter 1? We will explore the effects of applying transformations in this chapter.
In addition, because the Solow growth model tells us something about “the impact of saving and population growth on real income”, we may also regard \(\varepsilon\) as an error in a causal model. In this context, MRW assumed that \(\varepsilon\) is independent of \(s\) and \(n\). Effectively, this assumption justifies the use of causal language in their conclusions. They spend a lot of space to justify this assumption and they call it an identifying assumption. This terminology will show up regularly in your studies of applications of econometrics. We will discuss this phrase as we progress through this chapter, even though Chapter 1 has introduced this phrase using a different terminology.
Given what was discussed so far, MRW is ultimately trying to justify the use of linear regression. Linear regression is justifiable from both a prediction and causal perspective.
2.1.3 Testing claims
Another aspect which we did not study in Chapter 1, but would become relevant in the context of MRW is the testing of claims about some unknown quantity in the model found in Equation 2.4. What you should notice is that the Solow growth model implies some theoretical restrictions on some of its unknown quantities. In particular, if the Solow growth model were compatible with the data, we should be unable to reject the claim that \(\beta_1\) is actually equal to the negative of \(\beta_2\).
The problem is that we do not really know the values of \(\beta_1\) and \(\beta_2\) exactly even if the use of linear regression is justified. As you recall from Chapter 1, linear regression produces coefficients which are subject to variation. The importance of uncertainty quantification becomes apparent when we want to test whether the Solow growth model is compatible with the data. We will explore this aspect further in the next chapter.
2.1.4 Recovering functions of unknown quantities
Suppose that the “textbook” Solow growth model is compatible with the data. If that were the case, can we recover the unknown \(\alpha\)? What is \(\alpha\)? From your intermediate microeconomics and macroeconomics classes, \(\alpha\) in the Cobb-Douglas production function represents capital’s share of income.
Observe that \[\beta_1=\frac{\alpha}{1-\alpha} \Rightarrow \alpha=\frac{\beta_1}{1+\beta_1}.\] Therefore, \(\alpha\) is a function of \(\beta_1\). If we use linear regression to recover \(\beta_1\), then we can use it to recover \(\alpha\). What would the properties of this procedure? We will explore this aspect further in this chapter.
Another important research question is to measure the speed of convergence to the steady state, “after controlling for the determinants of the steady state, a phenomenon that might be called”conditional convergence.”“.5 To measure the speed of convergence, the theoretical result in Equation 2.2 needs to be expanded to allow for deviations from the steady state.
Let \(k(t)\) be the capital per unit of effective labor and \(y(t)\) be the income per unit of effective labor. Both are measured at any other time \(t\neq t^*\). Let \(k(t^*)\) and \(y(t^*)\) be the corresponding quantities at the steady state time \(t^*\).
We now recall some ideas from calculus and use them to form the required theoretical result. After that, we will be able to justify a model whose unknown quantities may be recovered using linear regression.
Form a first-order Taylor series approximation around the steady state \(k(t^*)\), we have \[\begin{eqnarray}\log k(t) &\approx & \log k(t^*)+\dfrac{d\log k}{dt}\Biggl|_{k=k(t^*)}\left(k-k(t^*)\right) \\
\log k &\approx &\log k(t^*)+\dfrac{1}{k(t^*)}\left(k-k(t^*)\right)\\ \Rightarrow \log k-\log k(t^*) &\approx &\dfrac{k-k(t^*)}{k(t^*)}\end{eqnarray}.\]
Recall also derivatives of logarithmic functions: \[\dfrac{d\log x\left(t\right)}{dt}=\dfrac{d\log x\left(t\right)}{dx}\cdot\dfrac{dx}{dt}=\dfrac{\dot{x}}{x}.\]
By definition, we have \(y\left(t\right)=Y\left(t\right)/A\left(t\right)L\left(t\right)\). We can then write \(\log y\left(t\right)=\alpha\log k\left(t\right)\). As a result, \[\dfrac{\dot{y}}{y}=\dfrac{d\log y\left(t\right)}{dt}=\alpha\dfrac{d\log k\left(t\right)}{dt}=\alpha\dfrac{\dot{k}}{k}.\]
Based on the Solow growth model, the growth rate of \(k\) is \[\dfrac{\dot{k}}{k}=\underbrace{sk^{\alpha-1}-\left(n+g+\delta\right)}_{G\left(k\right)}.\] A linear approximation of \(G\left(k\right)\) around the steady state \(k(t^*)\) is given by \[\begin{eqnarray} G\left(k\right) &\approx& G\left(k(t^*)\right)+G^{\prime}\left(k(t^*)\right)\left(k-k(t^*)\right) \\ &=& s\left(\alpha-1\right)\left(k(t^*)\right)^{\alpha-2}\left(k-k(t^*)\right)\\
&=& s\left(\alpha-1\right)\left(k(t^*)\right)^{\alpha-1}\left(\dfrac{k-k(t^*)}{k(t^*)}\right)\\
&=& s\left(\alpha-1\right)\left(k(t^*)\right)^{\alpha-1}\left(\log k-\log k(t^*)\right)\\
&=& -\left(1-\alpha\right)\left(n+g+\delta\right)\left(\log k-\log k(t^*)\right)\end{eqnarray}.\]
Putting all of these together, we have \[\begin{eqnarray} \dfrac{\dot{y}}{y} &=& -\alpha\left(1-\alpha\right)\left(n+g+\delta\right)\left(\log k-\log k(t^*)\right)\\
&=&-\left(1-\alpha\right)\left(n+g+\delta\right)\left(\alpha\log k-\alpha\log k(t^*)\right)\\
&=& -\left(1-\alpha\right)\left(n+g+\delta\right)\left(\log y-\log y(t^*)\right)\end{eqnarray}.\]
We can express the previous equation as a differential equation: \[\dfrac{d\log y\left(t\right)}{dt}=\lambda\left(\log y(t^*)-\log y\left(t\right)\right) \tag{2.5}\] where \(\lambda=\left(1-\alpha\right)\left(n+g+\delta\right)\).6\(\lambda\) measures the speed of convergence.
Note that Equation 2.5 is a differential equation and its solution is given by \[\log y\left(t\right)=\left(1-e^{-\lambda t}\right)\log y(t^*)+e^{-\lambda t}\log y\left(0\right).\] This solution implies that \[\log y\left(t\right)-\log y\left(0\right) = \left(1-e^{-\lambda t}\right)\left[\log y(t^*)-\log y\left(0\right)\right].\]
Let \(t=\overline{t}\), with \(\overline{t}\) being a specified year. We also exploit Equation 2.1 so that we can transform the measurements involving per unit of effective labor to measurements involving per capita instead. We also use the finding from Equation 2.3. Putting all these together, we have \[\begin{eqnarray}
&&\log \frac{Y(\overline{t})}{L(\overline{t})} - g\overline{t}-\log\frac{Y(0)}{L(0)} \\
&=& \left(1-e^{-\lambda \overline{t}}\right)\left[a+\dfrac{\alpha}{1-\alpha}\log s-\dfrac{\alpha}{1-\alpha}\log\left(n+g+\delta\right)+\varepsilon-\log\frac{Y(0)}{L(0)}\right]\end{eqnarray}.\]
We can then rewrite the previous equation so that we have some semblance of a linear regression model: \[\begin{eqnarray}&& \underbrace{\log \frac{Y(\overline{t})}{L(\overline{t})}-\log\frac{Y(0)}{L(0)}}_{Y} \\ &=& \underbrace{g\overline{t}+\left(1-e^{-\lambda \overline{t}}\right)a}_{\beta_0}+\underbrace{\left(1-e^{-\lambda \overline{t}}\right)}_{\beta_1}\underbrace{\log s}_{X_1} \\
&& \underbrace{-\left(1-e^{-\lambda \overline{t}}\right)}_{\beta_2}\underbrace{\log\left(n+g+\delta\right)}_{X_2} \\
&& \underbrace{- \left(1-e^{-\lambda \overline{t}}\right)}_{\beta_3}\underbrace{\log\frac{Y(0)}{L(0)}}_{X_3}\\
&& +\underbrace{\left(1-e^{-\lambda \overline{t}}\right)\varepsilon}_{\mathrm{error}}\end{eqnarray}\]
Since we want to recover \(\lambda\), we may recover it from \(\beta_3\). Once \(\overline{t}\) is specified and \(\beta_3\) is recovered, we can solve for \(\lambda\): \[\lambda=-\frac{1}{\overline{t}}\log(1+\beta_3),\] which is again a function of \(\beta_3\). Therefore, you encounter something similar to when we were trying to recover \(\alpha\). As always, an important question is whether or not linear regression will enable you to recover the desired unknown quantities. For the discussion involving speed of convergence, we need an even stronger assumption for the term \(\mathrm{error}\).7
2.2 Features of motivating example which require extensions of simple linear regression
Let me first establish some terminologies. What should we call \(Y\) and the \(X\)’s in Chapter 1? In light of what you have seen so far, we need to give them appropriate names. Calling them dependent and independent variables, respectively, is much too suggestive. Instead, we will call \(Y\) the regressand and the \(X\)’s as the regressors or predictors or covariates. When you apply lm(), then you are running a linear regression or computing a linear regression. When you run lm(Y ~ 1 + X1) or lm(Y ~ X1), you are running a linear regression of \(Y\) on a constant and \(X1\). Sometimes, reference to a constant is omitted, because the default is to include a constant. If you exclude the constant, then it is sometimes called regression without an intercept.
In this section, you will encounter a broad set of applied situations which will further refine what the words “linear” and “regression” mean when we write “linear regression”.
2.2.1 Transformations
Observe that in our motivating example we have computed the logarithms of variables. Taking logarithms is probably one of the most common transformations used in economics. Transformations may or may not have effects on regression coefficients. Transformations could either be linear or nonlinear.
In this subsection, we explore the effect of these transformations on regression coefficients and the coefficients of the best linear predictor. We also explore why transformations may be necessary.
2.2.1.1 Linear transformations
Examples of linear transformations include translation, scaling, and a combination of both. Translation or a location shift refers to adding or subtracting a constant amount to some variable. An example would be taking deviations from the mean. Scaling refers to multiplying or dividing by a constant amount to some variable. Some examples of scaling include changing millions USD to USD or changing USD to EUR. For the latter, the exchange rate has to stay constant. A combination of both translation and scaling is possible. Some examples include changing Celsius to Fahrenheit and standardizing variables.
All of these linear transformations have a common form. Let \(Y_{new}\) and \(X_{1,new}\) be the linearly transformed regressand and regressor, respectively. Let \(c_1\), \(c_2\), \(d_1\), and \(d_2\) be constants. Then from a random variable point of view, we have \[Y_{new}=c_1+c_2 Y,\ X_{1,new}=d_1+d_2 X_1. \tag{2.6}\] From the point of view of the observed values of random variables, we have \[Y_{t,new}=c_1+c_2 Y_t,\ X_{1t,new}=d_1+d_2 X_{1t}. \tag{2.7}\] Observe that the word “constant” means “same across all observed values”.
I will first demonstrate how lm() is affected if the regressand and/or regressors are linearly transformed.
We will use executive compensation data for the demonstration, as there is more room for transformations compared to the course evaluation data.8
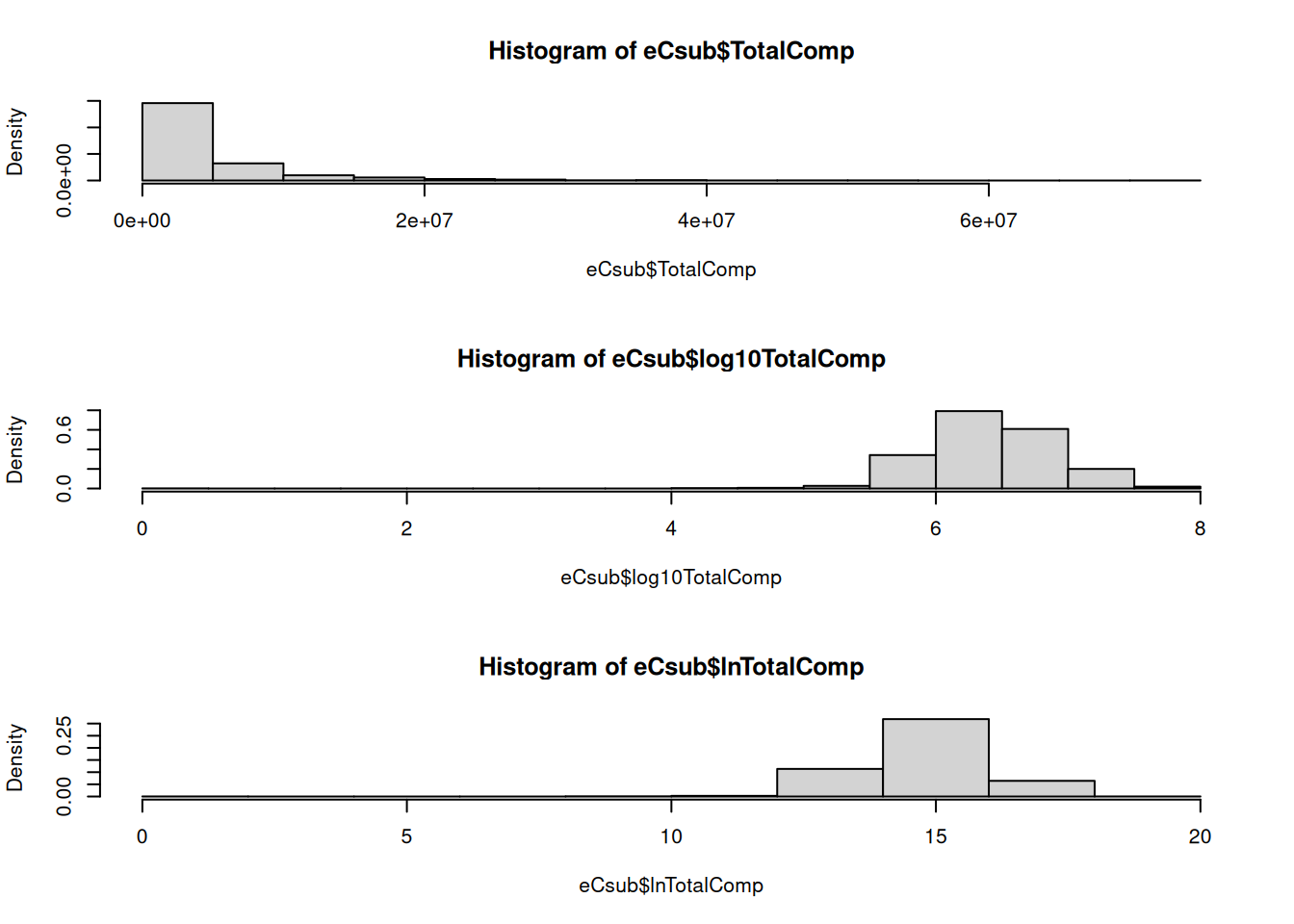
# Loading and cleaningexecComp <-read.csv("exec-comp.csv")head(execComp)
X Name Company Industry TotalCompMil
1 1 A. Bender COOPER COMPANIES INC Health 3.796108
2 2 A. Giannopoulos MICROS SYSTEMS INC IT 1.937943
3 3 A. Lafley PROCTER & GAMBLE CO Staples 19.086460
4 4 A. Mixon III INVACARE CORP Health 5.056142
5 5 A. Myers WASTE MANAGEMENT INC Industrial 5.695333
6 6 A. Perenchio UNIVISION COMMUNICATIONS INC Discretionary 0.000000
NetSalesMil Log10TotalComp SalaryThou
1 411.790 6.579339 461.3
2 400.191 6.287341 690.0
3 43373.000 7.280725 1600.0
4 1247.176 6.703819 948.0
5 11574.000 6.755519 1000.0
6 1311.015 NA 0.0
names(execComp)
[1] "X" "Name" "Company" "Industry"
[5] "TotalCompMil" "NetSalesMil" "Log10TotalComp" "SalaryThou"
summary(execComp) # What do you notice?
X Name Company Industry
Min. : 1 Length:1501 Length:1501 Length:1501
1st Qu.: 376 Class :character Class :character Class :character
Median : 751 Mode :character Mode :character Mode :character
Mean : 751
3rd Qu.:1126
Max. :1501
TotalCompMil NetSalesMil Log10TotalComp SalaryThou
Min. : 0.000 Min. : 0.0 Min. :0.000 Min. : 0.0
1st Qu.: 1.257 1st Qu.: 471.8 1st Qu.:6.100 1st Qu.: 450.0
Median : 2.533 Median : 1237.4 Median :6.404 Median : 650.0
Mean : 4.628 Mean : 5181.9 Mean :6.411 Mean : 696.8
3rd Qu.: 5.477 3rd Qu.: 4044.8 3rd Qu.:6.739 3rd Qu.: 900.0
Max. :74.750 Max. :257157.0 Max. :7.874 Max. :3993.0
NA's :6 NA's :1 NA's :7
# Focus on complete-case observationseCsub <-subset(execComp, (TotalCompMil>0& NetSalesMil>0))# Initial regressionreg1 <-lm(TotalCompMil ~1+ NetSalesMil, data = eCsub)# Centering regressandeCsub$TotalCompMilC <- eCsub$TotalCompMil-mean(eCsub$TotalCompMil)reg2 <-lm(TotalCompMilC ~1+ NetSalesMil, data = eCsub)# Centering regressor eCsub$NetSalesMilC <- eCsub$NetSalesMil-mean(eCsub$NetSalesMil)reg3 <-lm(TotalCompMil ~1+ NetSalesMilC, data = eCsub)# Centering regressand and regressorreg4 <-lm(TotalCompMilC ~1+ NetSalesMilC, data = eCsub)# Regression without an interceptreg5 <-lm(TotalCompMil ~-1+ NetSalesMilC, data = eCsub)# Scaling regressoreCsub$NetSalesBil <- eCsub$NetSalesMil/10^3reg6 <-lm(TotalCompMil ~1+ NetSalesBil, data = eCsub)# Scaling regressandeCsub$TotalCompBil <- eCsub$TotalCompMil/10^3reg7 <-lm(TotalCompBil ~1+ NetSalesMil, data = eCsub)# Scaling both regressand and regressorreg8 <-lm(TotalCompBil ~1+ NetSalesBil, data = eCsub)# Centering plus scaling, building on reg3 and reg6eCsub$NetSalesBilC <- eCsub$NetSalesBil -mean(eCsub$NetSalesBil)reg9 <-lm(TotalCompMil ~1+ NetSalesBilC, data = eCsub)stargazer::stargazer(reg1, reg2, reg3, reg4, reg5, type ="text", style ="aer", report ="vc", omit.stat ="all", no.space =FALSE,column.labels =c("reg1", "reg2", "reg3", "reg4", "reg5"), omit.table.layout ="n", model.numbers =FALSE, digits =4)
What do you notice about the regression coefficients? What would be the impact when you display and communicate your results?
Consider the following set of interpretations based on reg1:
CEOs whose firms have net sales of zero are predicted to have compensation of about 3.77 million dollars.
Firms having a million dollars more in terms of their net sales compared to other firms are predicted to compensate their CEOs by about 0.00017 million dollars more than other CEOs.9
Of course, there are easy ways of improving the communication of the results. For example, instead of saying 0.00017 million dollars, use 170 dollars. As you may have noticed, writing down interpretations becomes more verbose, more cumbersome, and sometimes unintelligible. An example of the latter is firms have net sales equal to zero.
Some improvements could be made simply by applying suitable linear transformations. Compare with the interpretations based on reg9:
CEOs whose firms have an average level of net sales of about 5.14 billion dollars are predicted to have compensation of about 4.63 million dollars.
Firms having a billion dollars more in terms of their net sales compared to other firms are predicted to compensate their CEOs by about 170000 dollars more than other CEOs.
Next, we look at the effect of transformations mathematically. We can look at the effect based on the data that we actually have. Recall from Section 1.1.2 that every actual value of \(Y\) is the sum of the fitted value \(\widehat{Y}_t\) and the residual \(\widehat{U}_t\): \[Y_t=\widehat{\beta}_0+\widehat{\beta}_1X_{1t}+\widehat{U}_t\] We now have to express the previous identity in terms of the transformed variables using Equation 2.7, i.e. \[\begin{eqnarray}\left(\frac{Y_{t,new}-c_1}{c_2}\right)&=&\widehat{\beta}_0+\widehat{\beta}_1\left(\frac{X_{1t,new}-d_1}{d_2}\right)+\widehat{U}_t \\ \Rightarrow Y_{t,new}-c_1 &=&\widehat{\beta}_0 c_2+ \frac{\widehat{\beta}_1c_2}{d_2}\left(X_{t,new}-d_1\right)+c_2\widehat{U}_t \\
\Rightarrow Y_{t,new} &=& \underbrace{\left(c_1+\widehat{\beta}_0 c_2-\frac{\widehat{\beta}_1c_2d_1}{d_2}\right)}_{\widehat{\alpha}_0}+\underbrace{\left(\frac{\widehat{\beta}_1c_2}{d_2}\right)}_{\widehat{\alpha}_1}X_{1t,new}+\underbrace{c_2\widehat{U_t}}_{\widehat{V}_t} \\ \Rightarrow Y_{t,new} &=& \widehat{\alpha}_0+\widehat{\alpha}_1 X_{1t,new}+\widehat{V}_t \end{eqnarray} \tag{2.8}\] We are now able to express the transformed \(Y\) as a fitted value and a residual. Observe the notation changes, because these are important to signal that things have changed.
A useful exercise would be to connect lm() demonstration of the effects of the transformations applied in the executive compensation dataset and the theoretical result obtained in Equation 2.8.
Another useful exercise is to mimic the derivation to obtain something similar to Equation 2.8 but for looking at the effect of transformations on random variables and the optimal coefficients of the best linear predictor. Start from the identity \[Y=\beta_0^*+\beta_1^* X_1+U,\] where \(\beta_0^*+\beta_1^* X_1\) is the best linear predictor and \(U\) is the error from best linear prediction of \(Y\) using \(X_1\). Use Equation 2.6 and mimic the earlier derivations. What are your findings? Do you notice similarities with Equation 2.8? Was this expected or unexpected?
2.2.1.2 Nonlinear transformations
One of the most useful nonlinear transformations in economics is the logarithmic transformation. Logarithmic transformations are related to growth rates. Therefore, logarithmic transformations are usually applied in settings where it makes sense to talk about relative differences.
We may use base 10 for monetary amounts, but base \(e \approx 2.718\) is used more frequently in economics. Let us look at the impact of these transformations on total compensation based on the executive compensation data.
Look at the effect of the choice of base on the regression coefficients. Only the intercept is different. If the intercept is not of any direct interest to your analysis, the choice of base may not be the most crucial issue.
How would you interpret the regression coefficients after applying a logarithmic transformation? Let us consider a more general setup and also start at the population level. In particular, we work with the best linear prediction of \(\log Y\) given \(\log X_1\). Let \(\beta_0^*\) and \(\beta_1^*\) be the coefficients of the best linear predictor and \(U\) be the error from best linear prediction of \(\log Y\) given \(\log X_1\). Therefore, we can write \[\log Y=\beta_0^* +\beta_1^* \log X_1 + U.\]
We can repeat the analysis found in Section 1.3.4 but this time taking into account the applied transformations:
The best linear prediction of \(\log Y\) if \(\log X_1=0\) is \(\beta_0^*\).
The best linear prediction of \(\log Y\) if \(\log X_1=z\) is \(\beta_0^*+\beta_1^*z\).
The best linear prediction of \(\log Y\) if \(\log X_1=z+1\) is \(\beta_0^*+\beta_1^*(z+1)\).
When we compare the best linear predictions of \(\log Y\) for cases where \(\log X_1=z+1\) against cases where \(\log X_1=z\), the predicted difference between those cases is \(\beta_1^*\).
The preceding statements are not the most understandable. What are the units? Are they in dollars? Furthermore, it is more natural to communicate in terms of the original variables rather than the transformed ones. Let us try again.
The best linear prediction of \(\log Y\) if \(X_1=1\) is \(\beta_0^*+\beta_1^*\log 1=\beta_0^*\).
The best linear prediction of \(\log Y\) if \(X_1=x>0\) is \(\beta_0^*+\beta_1^*\log x\).
The best linear prediction of \(\log Y\) if \(X_1=x+1\) is \(\beta_0^*+\beta_1^*\log(x+1)\).
When we compare the best linear predictions of \(\log Y\) for cases where \(X_1=x+1\) against cases where \(X_1=x\), the predicted difference between those cases is \(\beta_1^*\left[\log (x+1)-\log x\right]\).
There are definitely improvements in interpretation. Pay attention to the changes in the interpretation, especially for the intercept and for the predicted differences. For the latter, the predicted difference depends on the level of \(X_1\) unlike what you have seen in Section 1.3.4.
Since we have \[\begin{eqnarray}\log (x+1) - \log x &=& \log\left(\dfrac{x+1}{x}\right)\\ &=& \log\left[1+\left(\dfrac{x+1}{x}-1\right)\right] \\ & \approx & \dfrac{x+1}{x}-1 \\ &=&\dfrac{(x+1)-x}{x},\end{eqnarray}\] we can interpret differences in logarithms as relative differences. This point is what makes logarithmic transformations a very attractive option when communicating results. Finding relevant situations where relative changes make sense is crucial for determining whether a logarithmic transformation would be appropriate.
Let us now revisit
When we compare the best linear predictions of \(\log Y\) for cases where \(X_1=x+1\) against cases where \(X_1=x\), the predicted difference between those cases is \(\beta_1^*\left[\log (x+1)-\log x\right]\).
There is a relative difference in terms of the \(X_1\). Why? Because we are comparing cases where \(X_1=x+1\) against cases where \(X_1=x\) and the difference is \(\log(x+1)-\log x\). There is also a predicted relative difference in terms of \(Y\), because we are comparing the predictions for \(\log Y\) when \(X_1=x+1\) against predictions for \(\log Y\) when \(X_1=x\). The predicted relative difference is given by \(\beta_1^*\left[\log (x+1)-\log x\right]\), which could be expressed as \(\beta_1^*\) multiplied by a relative difference in \(X_1\).
The interpretation for the intercept is much more tenuous. Although we can write
The best linear prediction of \(\log Y\) if \(X_1=1\) is \(\beta_0^*+\beta_1^*\log 1=\beta_0^*\).
the interpretation is severely limited. First, we have to ask whether \(X_1=1\) is of interest. Second, we also have to consider expressing the result in terms of the original units of \(Y\). To “undo” the logarithm, we have to take the exponential. The issue is whether predictions about \(\log Y\) can be directly related to predictions about \(Y\). The prediction tasks are clearly different. In this sense, the simple act of “undoing” the logarithm is more complicated. You may feel that I am making a big deal out of this, but it is similar to an algebraic situation where \[\log \left(x^2\right) \neq \left(\log x\right)^2\] or a statistical situation where \[\log \left(\frac{1}{n}\sum_{t=1}^n Y_t\right)\neq \frac{1}{n}\sum_{t=1}^n \left(\log Y_t\right).\] Unfortunately, these points are often overlooked. Not even centering as you have seen in Section 2.2.1.1 would work in terms of aiding interpretation.
Given the previous discussions, it seems that it may be a good idea to focus on the regression coefficients aside from the intercept. We now apply the preceding analysis to interpret results from reg10 or reg11. In that context, we have “Firms having 1 percent more in terms of their net sales compared to other firms are predicted to compensate their CEOs by about 0.4 percent more than other CEOs.” An even better interpretation would be “Firms having 10 percent more in terms of their net sales compared to other firms are predicted to compensate their CEOs by about 4 percent more than other CEOs.”
Although we have provided a nice interpretation in terms of relative changes, the interpretation may itself be tenuous. This was a point formally raised by Silva and Tenreyro (2006). We will return to this issue later in this chapter. The bottom line is that the underlying issue can be traced to the nonlinear transformation of the regressand.
As an exercise, consider the case where a logarithmic transformation was only applied to \(X_1\) but not to \(Y\). To aid interpretation, you have a best linear predictor of \(Y\) given \(\log X_1\), having the form \(\beta_{0}^{*}+\beta_{1}^{*}\log X_1\).
Can you make a prediction for \(Y\) when \(X_1=0\)? If it is possible, provide the prediction. If not, explain why it is not possible.
Can you make a prediction for \(Y\) when \(\log X_1=0\)? If it is possible, provide the prediction. If not, explain why it is not possible.
Suppose \(X_1\) represents lot size of the property in square feet and \(Y\) is the sale price of the property. Is \(\log X_1=0\) a plausible value for making predictions about sale price? Explain.
Show that the predicted difference in \(Y\) between a group whose \(X_1=x\) and another group whose \(X_1=x+\Delta x\) is given approximately by \[\beta_{1}^{*}\left(\dfrac{\Delta x}{x}\right).\]
Let us say you obtained the following results from a linear regression of test scores (measured in points) on log income (where income is measured in thousands of dollars): \[557.8+36.42\log\ \mathrm{income}.\] Provide an interpretation of the regression coefficient of log income.
Continuing from Item 5, what would be the predicted difference in test scores for districts with average incomes of 10000 dollars versus 11000 dollars?
Continuing from Item 5, what would be the predicted difference in test scores for districts with average incomes of $20000 dollars versus 21000 dollars? Compare your answer with Item 6. What do you notice? Had it been income rather than the logarithm of income, would the predicted difference in test scores for Item 7 be the same as in Item 6?
Continuing from Item 5, what would be the predicted difference in test scores if one district has twice the as much as average income as another?
2.2.2 Including more regressors: algebraic considerations
From the point of view of using lm(), simply including more regressors into the syntax does not pose any additional problems. But if asked why we should include more regressors, then knowing how to copy and paste code using lm() is simply inadequate.
From a purely algebraic point of view, we could always just add regressors, provided that the regression coefficients could be computed uniquely. To illustrate, I return to the course evaluation dataset. Recall the linear regression of course_eval on female and the linear regression of course_eval on beauty found in Section 1.3.4.
First, let us explore what happens if you include a male regressor, i.e. we calculate a linear regression of course_eval on female and male.
ratings <- foreign::read.dta("TeachingRatings.dta") lm(course_eval ~1+ female, data = ratings)
# Let us add a male variable.ratings$male <-1- ratings$femalelm(course_eval ~1+ female + male, data = ratings)
Call:
lm(formula = course_eval ~ 1 + female + male, data = ratings)
Coefficients:
(Intercept) female male
4.069 -0.168 NA
In modern statistical software, their linear regression software routines would usually automatically drop regressors which are found to be “unfit” when calculating the regression coefficients. What do I mean by “unfit”?
Second, we explore what happens if we alter the first observation in beauty in such a way that the new variable beauty_mod is extremely close to beauty. This is definitely an absurd thought experiment but it gives a sense of computational instabilities which may arise.
I now try to illustrate what I mean by “unfit” and computational instability. In a sense, it can be best seen from our formula for \(\widehat{\beta}_1\) in Equation 1.3. When \(\sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)^2\) is equal to zero, \(\widehat{\beta}_1\) is undefined and cannot be computed in the first place. When \(\sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)^2\) is close to zero, \(\widehat{\beta}_1\) may be computed but would produce extreme values. Roughly, the computer demonstrations earlier illustrate the problems just described.
2.2.3 Including more regressors: non-algebraic considerations
From the theory justifying the use of lm() from a prediction perspective, a motivation to include more regressors or predictors would be to reduce mean squared error.
We can see this in the simplest way from Section 1.3.2. When we do not have any information to predict \(Y\), our best linear prediction is \(\mathbb{E}\left(Y\right)\). The mean squared error from using the best linear prediction in this case would be \[\mathbb{E}\left[\left(Y-\beta_0^*\right)^2\right]=\mathbb{E}\left[\left(Y-\mathbb{E}\left(Y\right)\right)^2\right]=\mathsf{Var}\left(Y\right).\] When we have additional information used for prediction, like the presence of \(X_1\), we can show that there is a reduction in the mean squared error relative to when we do not have additional information. Start from Equation 1.5 and substitute in the optimal coefficients of the best linear predictor of \(Y\) given \(X_1\) found in Equation 1.6. We obtain \[\begin{eqnarray}\mathbb{E}\left[\left(Y-\beta_0^*-\beta_1^*X_1\right)^2\right] &=& \mathbb{E}\left[\left(Y-\mathbb{E}\left(Y\right)+\beta_1^*\mathbb{E}\left(X_1\right)-\beta_1^*X_1\right)^2\right] \\ &=& \mathbb{E}\left\{\left[\left(Y-\mathbb{E}\left(Y\right)\right)-\beta_1^*\left(X_1-\mathbb{E}\left(X_1\right)\right)\right]^2\right\} \\ &=& \mathbb{E}\left[\left(Y-\mathbb{E}\left(Y\right)\right)^2\right] \\
&& -2\beta_1^*\mathbb{E}\left[\left(Y-\mathbb{E}\left(Y\right)\right)\left(X_1-\mathbb{E}\left(X_1\right)\right)\right]\\
&& +\left(\beta_1^*\right)^2\mathbb{E}\left[\left(X_1-\mathbb{E}\left(X_1\right)\right)^2\right]\\ &=& \mathsf{Var}\left(Y\right)-2\beta_1^* \mathsf{Cov}\left(X_1,Y\right) +\left(\beta_1^*\right)^2\mathsf{Var}\left(X_1\right) \\ &=& \mathsf{Var}\left(Y\right)-\left(\beta_1^*\right)^2\mathsf{Var}\left(X_1\right) \end{eqnarray}\] As a result, having additional information used for prediction will either lead to the same mean squared error (when \(\beta_1^*=0\)) or to a lower mean squared error (when \(\beta_1^*\neq 0\)).
From the theory justifying the use of lm() from a causality perspective, a motivation to include more regressors is to ensure the plausibility of \(\mathsf{Cov}\left(U,X_1\right)=0\) in a causal model like Equation 1.7. In practice, the concern is that \(\mathsf{Cov}\left(U,X_1\right)\neq 0\) in Equation 1.7 when the desired causal effect is the causal effect of \(X_1\) on \(Y\). If \(\mathsf{Cov}\left(U,X_1\right)\neq 0\), then linear regression will recover not the desired causal effect \(\lambda\). Although linear regression enables you to recover \(\beta_1^*\), it does not help you recover \(\lambda\), as seen most clearly in Equation 1.8.
There are definitely other ways to write down causal models which depart from what you saw in Equation 1.7. But they all share the same goal: recover a pre-defined causal effect. Whether or not linear regression can be used to recover such a causal effect can only be decided on a case-by-case basis.
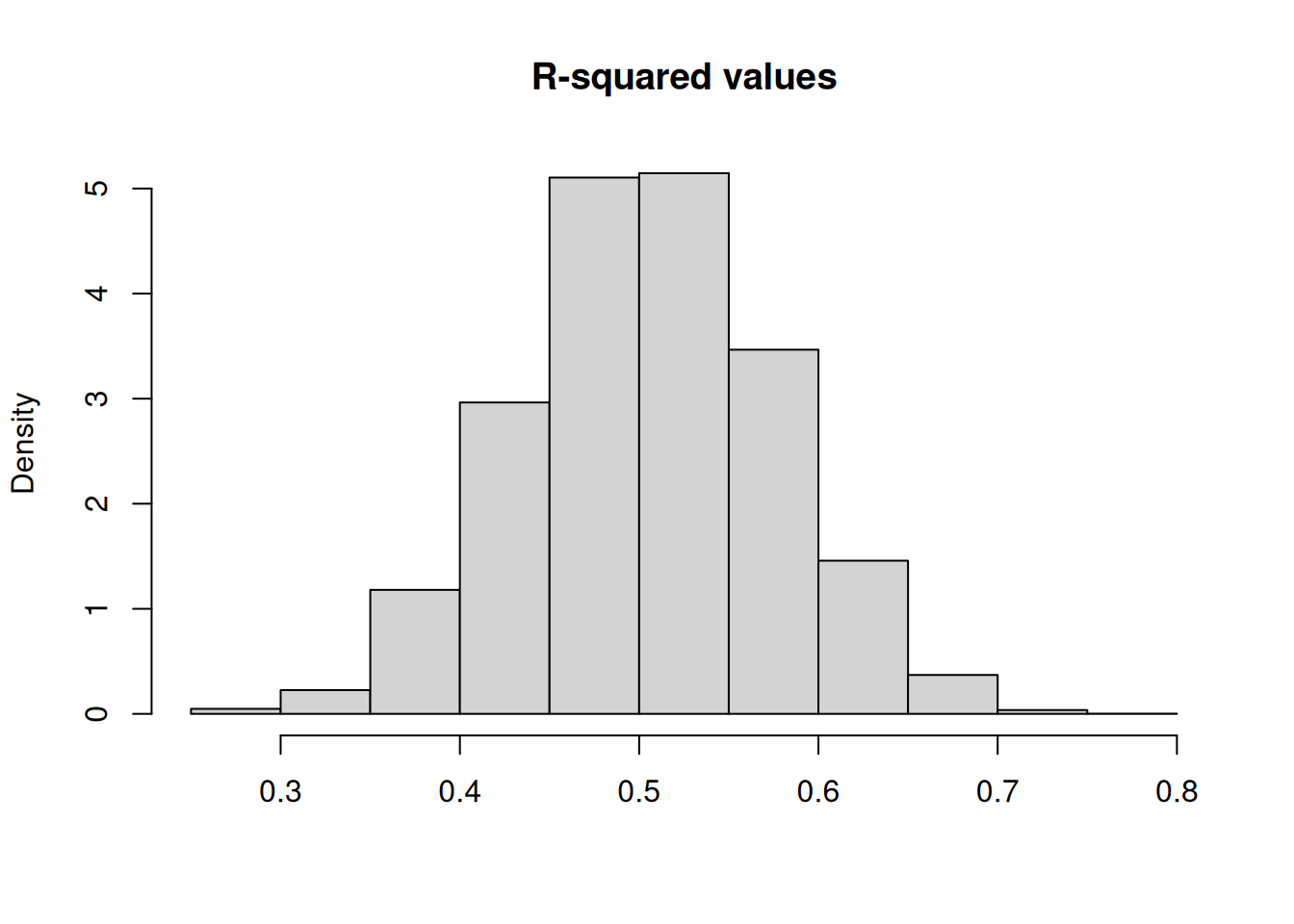
Although it is possible to include almost any regressor without prejudice, one has to be careful when using the terminology encountered in assessing the contribution of an additional regressor. Consider the following Monte Carlo simulation:
Generate tons of noise: \(X_1,\ldots,X_{50}, Y\) are all independent of each other and having the same distribution \(\sim N(0,1)\)
Look at the behavior of a goodness-of-fit measure10 called overall \(R^2\) computed after a linear regression of \(Y\) on \(X_1,\ldots, X_{50}\). We did not really define what this measure is. In our context, it would be “explained” as the ratio of the “explained variance” or “explained variation” provided by \(X_1,\ldots,X_{50}\) to the “total variance” or “total variation” in \(Y\). You may have noticed that the measure is not doing what it is supposed to do. Why?
reps <-10^4r2 <-numeric(reps)num.obs <-100num.vars <-50for (i in1: reps){ y <-rnorm(num.obs, mean =0, sd =1) x <-matrix(rnorm(num.obs*num.vars, mean =0, sd =1), nrow=num.obs) r2[i] <-summary(lm(y ~ x))$r.squared}hist(r2, freq=FALSE, xlab="", main="R-squared values")
2.2.4 Multiple linear regression as simple linear regression
The regression slope \(\widehat{\beta}_1\) discussed in Chapter 1 also has another algebraic property, which is extremely useful in practice.
The key ideas are that
Regression slopes are comparisons of linear predictions between different subgroups.
The expression for the slope in simple linear regression: \[\widehat{\beta}_1=\frac{\displaystyle\sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)\left(Y_{t}-\overline{Y}\right)}{\displaystyle\sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)^2} \]
Let us revisit our analysis of the executive compensation dataset.
adj.Comp <-residuals(lm(TotalCompMil ~1, data = eCsub))adj.Sales <-residuals(lm(NetSalesMil ~1, data = eCsub))lm(adj.Comp ~ adj.Sales -1)
Notice what were the sequence of commands which produced the outputs from lm():
Get the residuals from a linear regression of TotalCompMil on an intercept.
Get the residuals from a linear regression of NetSalesMil on an intercept.
(Residual regression) Compute the slope from a linear regression (without an intercept) of the residuals in the first step on the residuals in the second step.
The resulting slope is exactly equal to the slope computed from a simple linear regression of TotalCompMil and NetSalesMil. From an algebraic point of view, the regression slope \(\widehat{\beta}_1\) may be thought of as a linear regression of the regressand \(Y\) on the regressor \(X_k\) after both have been adjusted. The adjustment involves subtracting fitted values. In the special case we consider, the adjustment to \(Y\) involves subtracting the sample mean \(\overline{Y}\) from each observation of the regressand, while the adjustment to \(X_1\) involves subtracting the sample mean \(\overline{X}_1\) from each observation of the regressor. You must realize that these adjustments are precisely the fitted values from linear regressions of the regressand and regressors on a constant. The fitted values are precisely the sample means of the regressand and regressor.
What you have seen so far is the simplest version of the Frisch-Waugh-Lovell (FWL) theorem. The more general version is as follows.
Let \(Y_t\) be the value of the regressand for the \(t\)th observation. Let \[X_t^\prime=(1, X_{1t}, X_{2t}, \ldots X_{kt})\] be the corresponding value of the regressors. There are \(k\) regressors plus a “1”. Let us revisit our algebraic setup before when we used a spreadsheet layout. But this time, we cast everything in terms of matrices:
lm() computes the regression intercept and slopes, and together we call it \[\widehat{\beta}=\left(\widehat{\beta}_0,\widehat{\beta}_1,\ldots,\widehat{\beta}_k\right)^\prime.\]
Focus on the last entry of \(\widehat{\beta}\), namely \(\widehat{\beta}_k\).
Get the residuals from a linear regression of \(Y\) on all regressors except \(X_k\).
Get the residuals from a linear regression of \(X_k\) on all regressors except \(X_k\).
(Residual regression) Compute the slope from a linear regression (without an intercept) of the residuals in the first step on the residuals in the second step. The resulting slope is exactly equal to \(\widehat{\beta}_k\).
From an algebraic point of view, the regression slope \(\widehat{\beta}_k\) may be thought of as a linear regression of the regressand \(Y\) on the regressor \(X_k\) after both have been adjusted. The adjustment involves subtracting fitted values. Sometimes this adjustment is called “partialling-out”. But it would not be appropriate to call it “controlling for other regressors”. We shed more light on this aspect next.
2.2.5 Regression anatomy
We have already motivated why we would include additional regressors. We also explored the algebraic nature of the regression slopes of these additional regressors. We now are concerned with the interpretation and communication of results. We will find guidance in the long-run “order” of the regression coefficients produced by lm().
Recall that in the simple linear regression case, the regression coefficients produced by lm() has some “order” in the long run and this long run is related to the coefficients \(\left(\beta_0^*,\beta_1^*\right)\) of the best linear predictor. We extend our setup in Section 1.3.2 and now predict scalar \(Y\) when you have information about a vector \(X=\left(1,X_{1},\ldots,X_{k}\right)^{\prime}\). What stays the same? What changes? For the best linear predictor, the choice set is now the set of all \(\beta=\left(\beta_{0},\beta_{1},\ldots,\beta_{k}\right)^{\prime}\in\mathbb{R}^{k+1}\) such that the prediction rule has the form \[\beta_{0}+\beta_{1}X_{1}+\cdots+\beta_{k}X_{k}=X^{\prime}\beta.\] We still want to minimize the mean squared error with the an optimal choice of \(\beta\): \[\min_{\beta} \mathbb{E}\left[\left(Y-X^{\prime}\beta\right)^2\right].\] It can be shown that the coefficients of the best linear predictor are given in the vector: \[\beta^{*}=\left[\mathbb{E}\left(XX^{\prime}\right)\right]^{-1}\mathbb{E}\left(XY\right).\] The properties of the prediction error \(U=Y-X^{\prime}\beta\) still stay the same (again with minor notation changes).
We now try to give an interpretation of the last component of \(\beta^{*}\), for concreteness (this is much more general than it appears). The last coefficient has the following interpretation: \[\beta_{k}^{*}=\dfrac{\mathsf{Cov}\left(Y,V_{k}\right)}{\mathsf{Var}\left(V_{k}\right)}. \tag{2.9}\] The form is reminiscent of the slope found in Equation 1.6. But what is \(V_k\)?
Consider a prediction task where you will predict \(X_k\) using \(X_{-k}^{\prime}=\left(1,X_{1},X_{2},\ldots,X_{k-1}\right)\) using a prediction rule \[\delta_0+\delta_1 X_1+\cdots +\delta_{k-1} X_{k-1}=X_{-k}^{\prime}\delta^{*}.\] Suppose you have found the optimal coefficients \(\delta^*=\left(\delta_{0}^*,\delta_{1}^*,\ldots,\delta_{k-1}^*\right)^{\prime}\in\mathbb{R}^{k}\) of the best linear predictor of \(X_{k}\) (a scalar random variable) using \(X_{-k}^{\prime}=\left(1,X_{1},X_{2},\ldots,X_{k-1}\right)\). We can always write \[X_{k}=X_{-k}^{\prime}\delta^{*}+V_{k},\] where \(V_{k}\) is the error from best linear prediction. We must also have \[Y=X^{\prime}\beta^{*}+U,\] where \(u\) is another error from best linear prediction.
To prove that the last coefficient has the interpretation shown in Equation 2.9, we need to show that \[\begin{eqnarray}\mathsf{Cov}\left(Y,V_{k}\right) & = & \beta_{k}^{*}\mathsf{Cov}\left(X_{k},V_{k}\right)+\mathsf{Cov}\left(U,V_{k}\right) \\
&=&\beta_{k}^{*}\mathsf{Var}\left(V_{k}\right)+\mathsf{Cov}\left(U,V_{k}\right).\end{eqnarray}\] Now, try showing that \[\mathsf{Cov}\left(U,V_{k}\right)=\mathsf{Cov}\left(U,X_{k}-X_{-k}^{\prime}\delta^{*}\right)=0.\] After that, the result in Equation 2.9 immediately follows.
Another way to approach Equation 2.9 is as follows. Suppose you have found the coefficients of the best linear predictor of \(Y\) using \(X_{-k}\) instead so that \[Y=X_{-k}^{\prime}\gamma^{*}+W.\] Here \(W\) is the error from the best linear prediction of \(Y\) given \(X_{-k}\). Try to show that \[\beta_{k}^{*}=\dfrac{\mathsf{Cov}\left(W,V_{k}\right)}{\mathsf{Var}\left(V_{k}\right)}.\]
The bottom line of all of these arguments is that we cannot interpret \(\beta_k^*\) as the “effect of increasing \(X_k\) on \(Y\) holding all other regressors constant”. Some textbooks do adopt this interpretation. But the only way to get to this interpretation is to have a causal model and justify its origin, or at least to defend why the regression coefficients will have a causal interpretation.
Another (potentially) misleading aspect to the phrase “effect of increasing \(X_k\) on \(Y\) holding all other regressors constant”, is the part about “holding all other regressors constant”. As you may have seen from the regression anatomy, you don’t exactly “hold all other regressors constant”, you adjust for the presence of other regressors in a very particular way. As a result, it may be prudent, for the sake of communication, to adopt our “template” for interpreting regression coefficients. In particular, consider the case where \(\beta_0^*+\beta_1^* X_1+\beta_2^* X_2\) is the best linear predictor of \(Y\) given \(X_1\) and \(X_2\). It is not going to be surprising that lm(), which produces \(\widehat{\beta}_0\), \(\widehat{\beta}_1\), and \(\widehat{\beta}_2\), has a “long-run” order which enables you to recover \(\beta_0^*\), \(\beta_1^*\), and \(\beta_2^*\). Then, we have:
The best linear prediction of \(Y\) when \(X_1=0\) and \(X_2=0\) is \(\beta_0^*\).
The best linear prediction of \(Y\) when \(X_1=x_1\) and \(X_2=x_2\) is \(\beta_0^*+\beta_1^* x_1+\beta_2^* x_2\).
The best linear prediction of \(Y\) when \(X_1=x_1+1\) and \(X_2=x_2\) is \(\beta_0^*+\beta_1^* (x_1+1)+\beta_2^* x_2\).
When we compare the best linear predictions of \(Y\) for cases where \(X_1=x_1+1\) and \(X_2=x_2\) against cases where \(X_1=x_1\) and \(X_2=x_2\), the predicted difference between those cases is \(\beta_1^*\).
You have to compare how different the statements above are to Section 1.3.4. You would notice that we are still comparing different groups having certain labels – one group has \(X_1=x_1+1\) and \(X_2=x_2\) while the other has \(X_1=x_1\) and \(X_2=x_2\). You may think the \(X_2=x_2\) means \(X_2\) was held constant, but we just so happen to select the groups in such a way that the level of \(X_2\) was the same. You can also try to provide a predictive interpretation for \(\beta_2^*\).
2.3 Other important extensions of simple linear regression occurring in practice
2.3.1 Dummy variables
You have already encountered dummy variables before. The variable female in the course evaluation dataset is an example of a dummy variable. We called it a binary variable in Chapter 1, but the terms are interchangable. You may also call them categorical variables. In R, they are usually called factor11 variables.
Usually, binary variables are used for the presence or absence of a characteristic. It is also used to look into mutually exclusive but exhaustive subgroups. For the case of female, instructors were divided into two sexes: male and female. They are treated as mutually exclusive, in the sense that when one is ascribed a male label, then that individual can no longer be ascribed a female label. The male and female categories are mutually exhaustive, in the sense that all observations are either male or female.
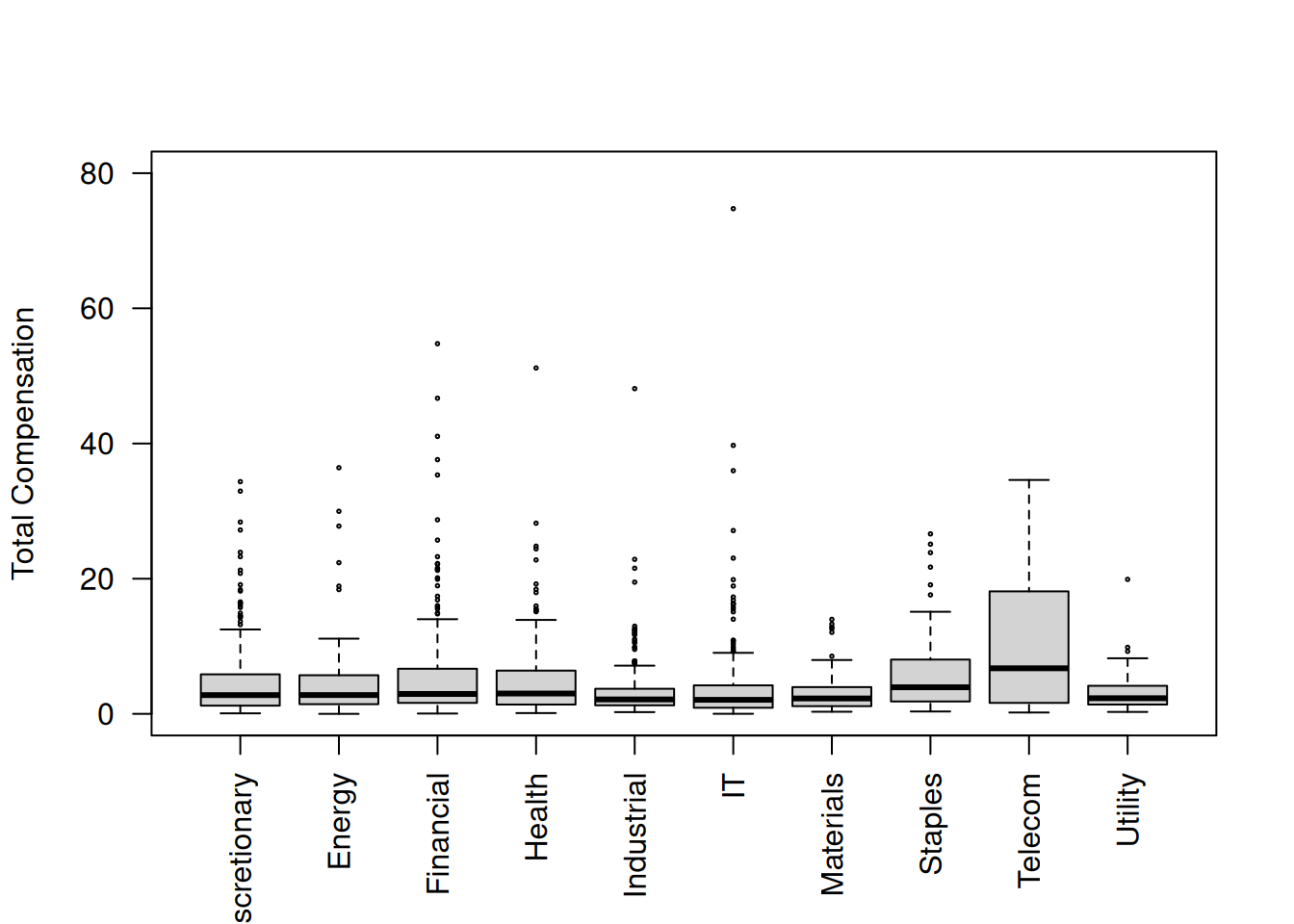
We now consider what happens if you have multiple labels, or if you wish, multiple subgroups, where the subgroups are mutually exclusive. We return to our executive compensation dataset once again. In particular, let us focus on including regressors representing the industry of the firm being represented by the CEO.
The preceding calculations is essentially reproducing the industry averages. The presentation is just slightly different but carry exactly the same information. There are 10 industries in the sample. Putting in as.factor(Industry) treats the variable Industry which labels the type of industry into 9 separate dummy variables. Each dummy variable becomes an indicator of a particular industry. For example, the regressor coded as.factor(Industry)Energy in the results is really an energy industry indicator. What that means is that it is equal to 1 if the CEO works for a company that belongs in the energy industry and 0 otherwise. The other dummy variables are defined in a similar manner.
What if we look at the logarithm of total compensation? How would you articulate the findings below? What if you want to express the findings in terms of total compensation rather than the logarithm of total compensation?
What happens when we include other regressors which are not dummy variables? Let us reconsider the linear regression of total compensation on net sales, first introduced in Section 2.2.1.1, by including industry dummy variables.
lm(log10TotalComp ~ log10NetSales +as.factor(Industry), data = eCsub)
It becomes unwieldy to interpret so many coefficients. In practice, some coefficients are of direct interest and some coefficients are not. The research question will usually lead you to this determination. Here, I focus on the coefficient of log10NetSales. To understand this coefficient in the current context, we have the Frisch-Waugh-Lovell theorem discussed in Section 2.2.4.
reg.comp.remove.ind <-lm(log10TotalComp ~as.factor(Industry), data = eCsub)reg.sales.remove.ind <-lm(log10NetSales ~as.factor(Industry), data = eCsub)# Frisch-Waugh-Lovelllm(residuals(reg.comp.remove.ind) ~residuals(reg.sales.remove.ind) -1, data = eCsub)
reg.comp.remove.ind and reg.sales.remove.ind are really producing coefficients which involve industry averages. Applying residuals() produces deviations from the corresponding industry averages. What this means is that if the observation belongs to the energy industry (for example), then the average for the energy industry is used for calculating the deviation.
As a result, one possible way of interpreting the coefficient of log10NetSales is as follows. After subtracting corresponding industry-level averages from net sales and total compensation, total compensation for CEOs having 10% more net sales than other firms are predicted to be 4.3% higher than the total compensation for CEOs of those other firms.
There are other alternatives to writing an interpretation for the coefficient of log10NetSales. One could proceed along the same lines as Section 1.3.4. For example: Consider firms belonging to the energy industry. We find that the total compensation of CEOs of those firms whose net sales are 10% higher than other firms are predicted to be 4.3% higher than the total compensation for CEOs of those other firms.
As further practice, determine whether the preceding interpretation also applies to those in a different industry, say the telecom industry. What do you notice? Furthermore, can we make comparisons between for CEOs belonging to different industries?
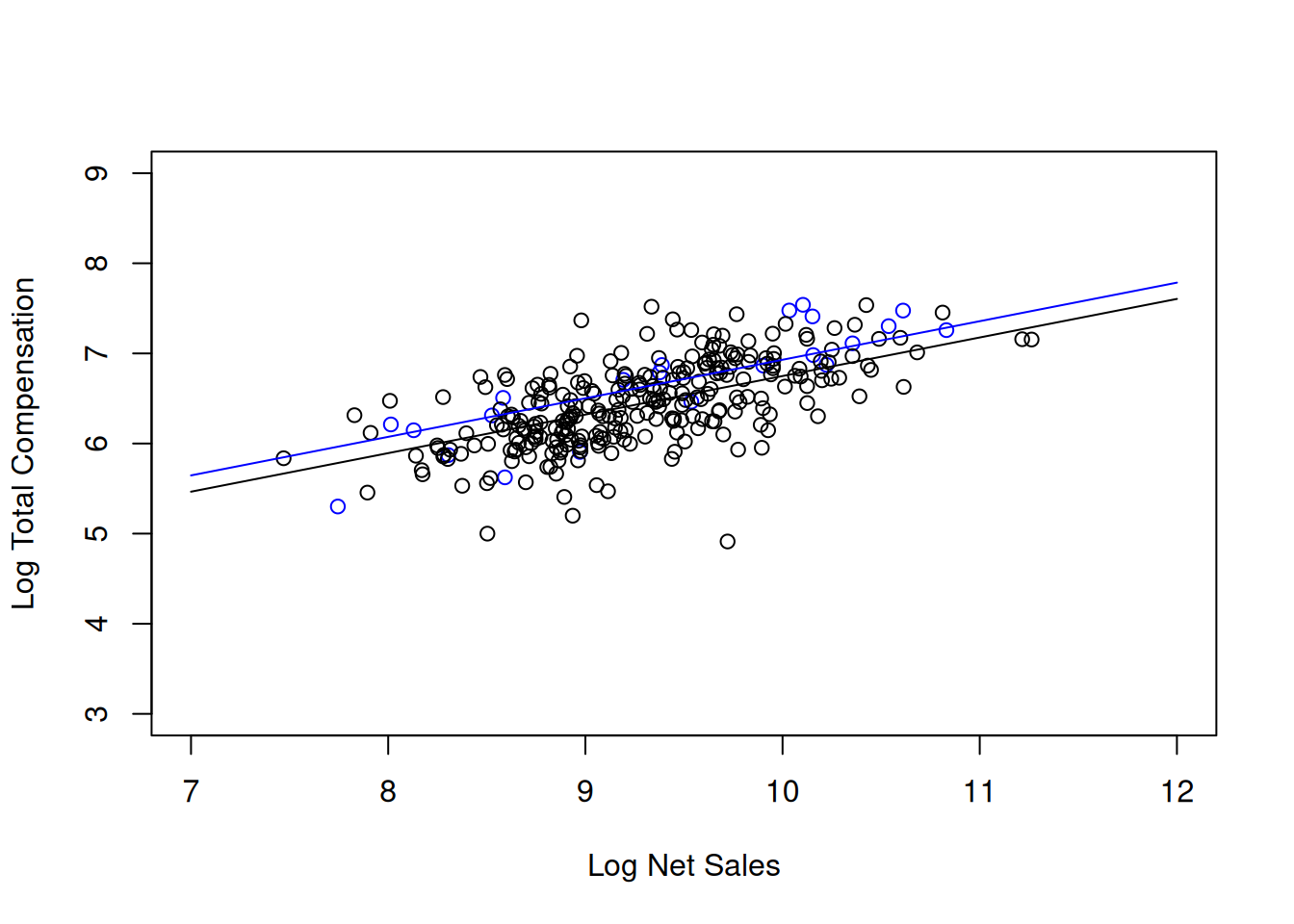
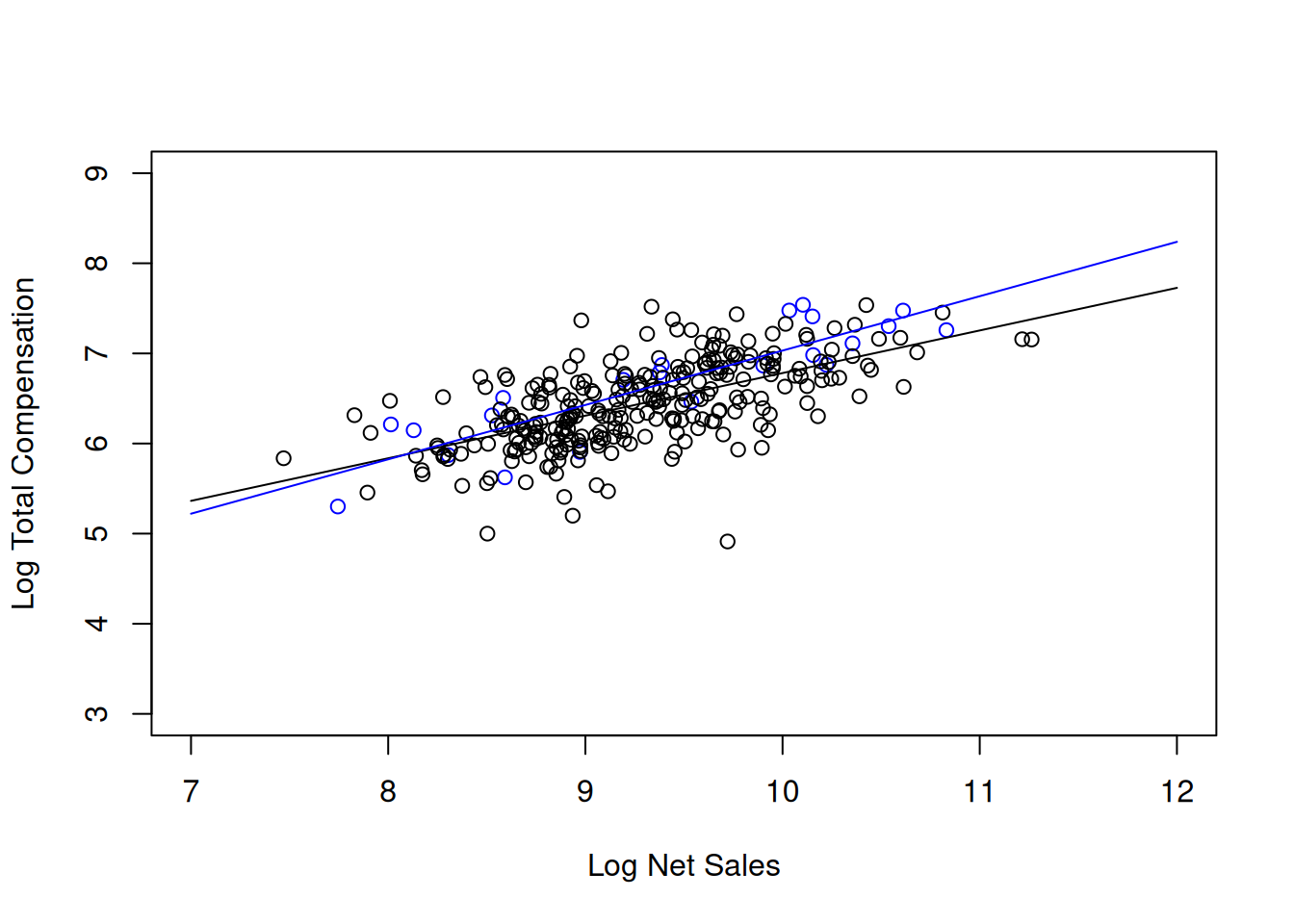
After all these interpretations resulting from the inclusion of industry dummy variables, so you might wonder where exactly can you find industry differences? I show a scatterplot of log10TotalComp and log10NetSales only for the discretionary industry and the telecom industry. What do you notice about the fitted regression lines?
When we start working on interaction terms in Section 2.3.3, we may allow for richer industry differences.
2.3.2 Polynomial terms
So far, we have considered prediction rules of the form \(\beta_0+\beta_1 X_1\) for the simple case and \(\beta_0+\beta_1 X_1+\cdots+\beta_k X_k\) for the case of multiple predictors. It is possible to add even more flexibility for these linear prediction rule by adding polynomial terms of \(X_1\), for example, \(X_1^2, X_1^3, \ldots, X_1^p, \ldots\).12 The result is no different from the case of having multiple predictors. It is not very important to derive the best linear predictor but we assume that such an object will exist.
I now discuss one reason why it could be appropriate to include polynomial terms. Consider the simplest linear predictor \(\beta_0+\beta_1X_1\). We add polynomial terms as described earlier. The optimization problem becomes \[\min_{\beta_{0},\beta_{1}, \ldots, \beta_p}\mathbb{E}\left[\left(Y-\beta_{0}-\beta_{1}X_{1}-\beta_2X_1^2-\cdots \beta_p X_1^p\right)^{2}\right].\] The minimized value of the objective function will be decreasing as \(p\to\infty\). Eventually, the mean squared error must approach a limit. In this case, it would be zero, because the smallest value that the mean squared error can attain is zero. There is a sense in which the best linear predictor converges to an object as you add more and more higher-degree polynomial terms as \(p\to\infty\).13 The limiting quantity can be shown to be an object called the conditional expectation of \(Y\) given \(X_1\), denoted as \(\mathbb{E}\left(Y|X_1\right)\), i.e. \[\lim_{p\to\infty} \mathbb{E}\left(\mathbb{E}\left(Y|X_1\right)-\left(\beta_0^*+\beta_1^*X_1+\ldots+\beta_p^*X_1^p\right)\right)^2=0. \tag{2.10}\] A natural question is to describe what make a conditional expectation different from the best linear predictor. We will explore this aspect in a separate section. The convergence results suggest that perhaps a conditional expectation is a better way to make predictions compared to the best linear predictor.
Another reason why it may be appropriate to include polynomial terms is related to economics. Qualitative statements involving “diminishing returns”, “increasing marginal product”, and other similar phrasings usually involve choosing prediction rules which incorporate nonlinearities in the regressors. In practice, you will usually see quadratic functions of the regressors. Why would these quadratic functions capture qualitative statements such as “diminishing returns”? It boils down to interpretations of the optimal coefficients of a best linear predictor which incorporates nonlinearities in the regressors.
Consider the best linear prediction of \(Y\) using \(X_1\) and \(X_1^2\). The best linear predictor is given by \(\beta_0^*+\beta_1^*X_1+\beta_2^* X_1^2\).
You can now provide an interpretation of \(\beta_0^*\).
The best linear prediction of \(Y\) given \(X_1=x\) is given by \(\beta_0^*+\beta_1^*x+\beta_2^* x^2\).
Let \(\Delta x\) be a difference between two groups with respect to their \(X_1\). The best linear prediction of \(Y\) given \(X_1=x+\Delta x\) is given by \(\beta_0^*+\beta_1^*(x+\Delta x)+\beta_2^* (x+\Delta x)^2\).
The difference between the best linear predictions is equal to \[\beta_1^* \Delta x+\beta_2^* \left(2x\Delta x + \left(\Delta x\right)^2\right) = \left(\beta_1^*+2\beta_2^* x +\beta_2^*\Delta x\right)\Delta x.\] Therefore, on the basis of a per unit difference we have \[\dfrac{\beta_1^* \Delta x+\beta_2^* \left(2x\Delta x + \left(\Delta x\right)^2\right)}{\Delta x} = \beta_1^*+2\beta_2^* x +\beta_2^*\Delta x\]
When \(\Delta x\) is small enough, \(\beta_1^*+2\beta_2^* x\)approximates the predicted per unit difference in \(Y\).
Whether or not \(\Delta x\) is small, the predicted difference depends on the level \(x\). In this sense, introducing a nonlinearity in the regressor \(X_1\) allows you to have predicted differences (or per unit difference) which depend on the level of \(X_1\). In contrast, if you do not have the nonlinearity in \(X_1\), the predicted difference (or per unit difference) does not depend on the level of \(X_1\). Finally, notice that it is impossible and downright ridiculous to “hold all other regressors constant” in this context (Why?)
To see how “diminishing returns” and other related qualitative statements may be accommodated, observe that what we found so far involves may be thought of as taking the first two derivatives of the best linear predictor with respect to \(X_1\), evaluated at the level \(X_1=x\), i.e. \[\dfrac{\partial\left(\beta_0^*+\beta_1^*X_1+\beta_2^* X_1^2\right)}{\partial X_1} \bigg|_{X_1=x} = \beta_1^*+2\beta_2^* X_1 \bigg|_{X_1=x} =\beta_1^*+2\beta_2^*x,\] and \[\dfrac{\partial^2\left(\beta_0^*+\beta_1^*X_1+\beta_2^* X_1^2\right)}{\partial X_1^2} \bigg|_{X_1=x} = 2\beta_2^*.\]
“Increasing at a decreasing rate” could be thought of as having \(\beta_1^*+2\beta_2^*x>0\) and \(2\beta_2^*<0\). You are then able to accommodate the required qualitative statement whenever the range of \(x\) is \(x<-\dfrac{\beta_1^*}{2\beta_2^*}\) and \(\beta_2^*<0\). You should be able to try out different qualitative statements and proceed in a similar manner.
In practice, turning points are also of interest. For example, if \(\beta_2^*<0\), then \(x=-\dfrac{\beta_1^*}{2\beta_2^*}\) is the level \(x\) which maximizes the best linear predictor. This is also the level of \(x\) where there is a change in the qualitative behavior of the best linear predictor. When \(x<-\dfrac{\beta_1^*}{2\beta_2^*}\), the best linear predictions are increasing in \(x\). When \(x>-\dfrac{\beta_1^*}{2\beta_2^*}\), the best linear predictions are decreasing in \(x\). Therefore, \(x=-\dfrac{\beta_1^*}{2\beta_2^*}\) is also a turning point.
As you may have noticed it takes some extra analysis to accommodate, interpret, and communicate qualitative statements like “diminishing returns” in a quantitative manner. We can simplify things by applying some centering.
Let \(x\) be a pre-specified or given level of \(X_1\). Define \(X_{1,new}=X_1-x\). We can always write \(Y=\beta_0^*+\beta_1^* X_1+\beta_2^* X_1^2+U\) where \(U\) is the error from best linear prediction of \(Y\) given \(X_1\) and \(X_1^2\). After some algebraic manipulations, we can write \[Y = \underbrace{\beta_0^*+\beta_1^* x+\beta_2^* x^2}_{\alpha_0^*} + \underbrace{\left(\beta_1^*+2\beta_2^* x\right)}_{\alpha_1^*} X_{1,new} + \underbrace{\beta_2^*}_{\alpha_2^*}X_{1,new}^2 +U.\] Clearly, \(U\) is the error from best linear prediction of \(Y\) given \(X_{1,new}\) and \(X_{1,new}^2\). Observe that \(\alpha_1^*=\beta_1^*+2\beta_2^* x\). Therefore, with just a centering, you can read off immediately the approximate per unit difference \(\beta_1^*+2\beta_2^* x\). This is very convenient not just from a communication point of view but also when quantifying uncertainty. We will explore the latter in the next chapter. But for the former, the choice of level for \(x\) is also important. Some use “interesting quantities” for \(x\), say the average. As a result, the predicted per unit difference is relative to some average.
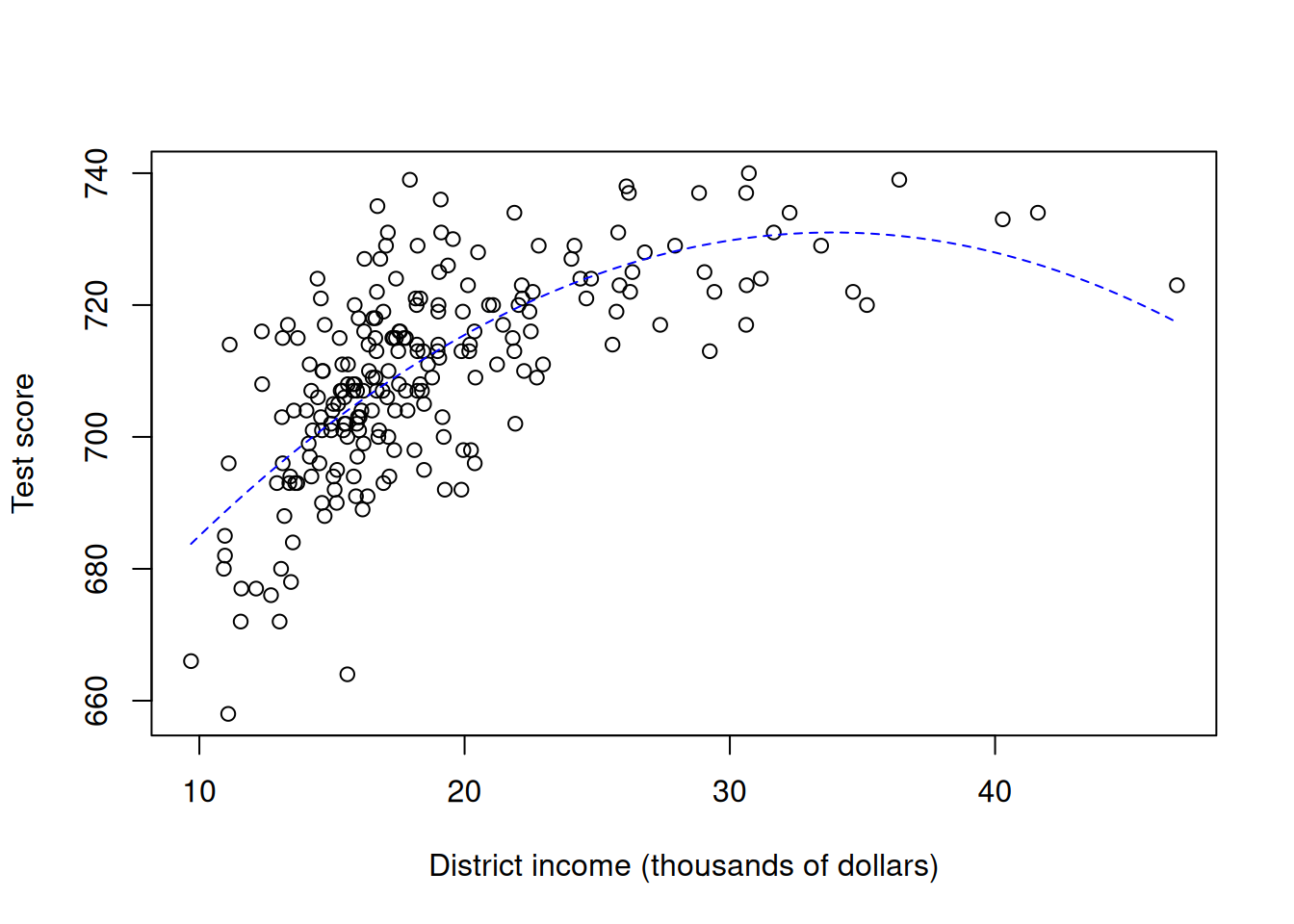
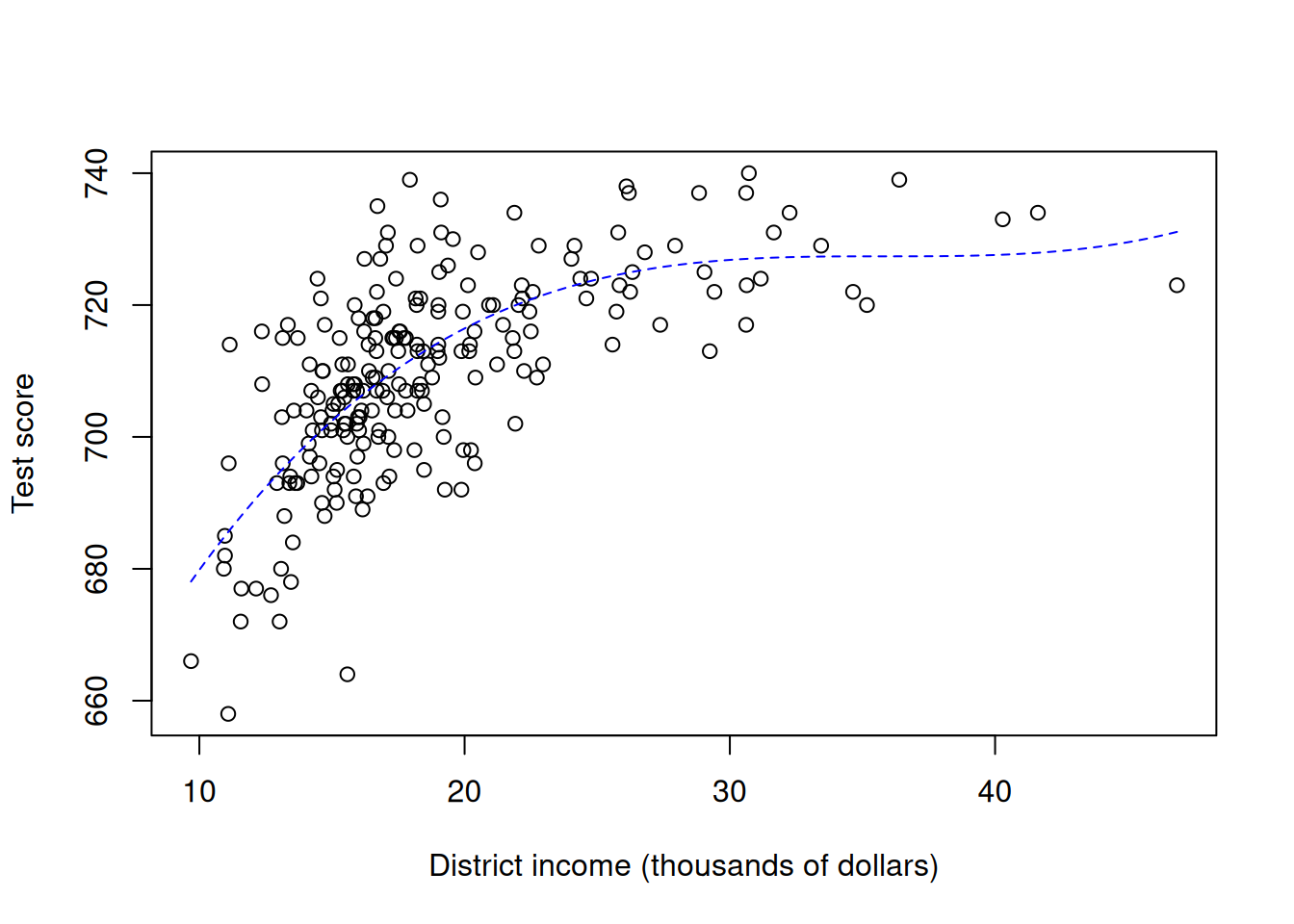
I will illustrate with district test scores \(Y\) and average district income \(X_1\). These data are obtained from Massachusetts public elementary school districts in 1998. Pay attention to how polynomial terms are added. Also observe the connection between the approximate predicted per unit difference and how it could be read off from results of a linear regressioon after an appropriate recentering.
mcas <-read.csv("mcas.csv")lm(totsc4 ~ percap +I(percap^2), data = mcas)
# (Approximate) predicted per unit difference, level of percap at mean(percap)results <-lm(totsc4 ~ percap +I(percap^2), data = mcas)coef(results)[[2]]+2*coef(results)[[3]]*mean(mcas$percap)
plot(mcas$percap, mcas$totsc4, xlab ="District income (thousands of dollars)", ylab ="Test score")# Visualizationcurve(cbind(1, x, x^2, x^3) %*%coef(lm(totsc4 ~ percap +I(percap^2) +I(percap^3), data = mcas)), lty ="dashed", add =TRUE, col ="blue")
A relevant question to ask is what are the benefits and costs of adding more and more polynomial terms. When the task is prediction, the answer rests on the ability to reduce mean squared error. You will likely encounter discussions about these aspects in a course devoted to prediction and will come across concepts as the ability to predict outside of the sample you currently have.14 When the task is to recover causal effects, it would depend on the assumed causal model and what causal effect is of interest.
2.3.3 Interaction terms
The product of two or more regressors is sometimes called an interaction term.15
Interaction terms may arise when you extend the idea of having polynomials of higher degree but you have more than one regressor. For example, a quadratic function of \(X_1\) could be written as \(aX_1^2+bX_1+c\) Extending the idea to two regressors, a quadratic function of \(X_1\) and \(X_2\) could be written as \(aX_1^2+bX_1+cX_2^2+dX_2+eX_1X_2+f\).16 Observe that there is a term involving \(X_1\) multiplied by \(X_2\). That would be an interaction term in our context.
Why would these interaction terms be of interest? One answer extends the finding that adding for nonlinearities in the regressors produces predicted per unit differences which depend on the level of the regressor. Consider the best linear predictor of the form \(\beta_0^*+\beta_1^*X_1+\beta_2^*X_2+\beta_3^* X_1 X_2\).
You can now provide an interpretation of \(\beta_0^*\).
The best linear prediction of \(Y\) when \(X_1=x_1\) and \(X_2=x_2\) is \(\beta_0^*+\beta_1^*x_1+\beta_2^*x_2+\beta_3^* x_1x_2\).
The best linear prediction of \(Y\) when \(X_1=x_1+1\) and \(X_2=x_2\) is \(\beta_0^*+\beta_1^*(x_1+1)+\beta_2^*x_2+\beta_3^* (x_1+1)x_2\).
When we compare the best linear predictions of \(Y\) for cases where \(X_1=x_1+1\) and \(X_2=x_2\) against cases where \(X_1=x_1\) and \(X_2=x_2\), the predicted difference between those cases is \(\beta_1^*+\beta_3^*x_2\).
In a similar fashion, when we compare the best linear predictions of \(Y\) for cases where \(X_1=x_1\) and \(X_2=x_2+1\) against cases where \(X_1=x_1\) and \(X_2=x_2\), the predicted difference between those cases is \(\beta_2^*+\beta_3^*x_1\).
Just like in the case where we added polynomial terms, the predicted differences depend on the levels of the regressors. The important distinction this time is which regressor enters the predicted difference.
In addition, the comparisons need not involve just a unit difference. Try writing down the predicted differences when comparing best linear predictions for cases where \(X_1=x_1+\Delta x\) and \(X_2=x_2\) against cases where \(X_1=x_1\) and \(X_2=x_2\). Do something similar for \(X_2\) as well. What would be the predicted per unit differences? Would an approximation be needed by treating \(\Delta x\) is small?
Another exercise to try is to determine the effect of centering, similar to what I did earlier when polynomial terms were included. I demonstrate what you could expect from a theoretical analysis by computing a linear regression of the standardized outcome on a principles of microeconomics final exam at the University of Michigan on percentage of classes attended atndrte, prior college GPA priGPA, and their interaction.
We focused on cases where both \(X_1\) and \(X_2\) are continuous. What you saw earlier regarding centering may not necessarily be a good idea when either \(X_1\) or \(X_2\) are binary.
It is also possible to have interaction terms involving a continuous and a binary regressor. For example, let us revisit the executive compensation dataset.
If you interact the industry dummy variables with net sales, then, in our context, you will get 9 interaction terms. From here, can you figure out in what sense will industry differences are reflected in the results? How do the results differ from the linear regression without interaction terms?
We can also visualize the results and try to understand industry differences. We focus once again on the discretionary and telecom industries so as not to crowd the visualization with too much information.
As you may have noticed, the inclusion of regressors can make interpretation substantially difficult to communicate, especially when we try to allow for nonlinearities in the regressors.
A very special case, which is extremely useful in practice, arises when both \(X_1\) and \(X_2\) are binary. But as you recall, having only binary regressors present in linear regressions ultimately lead to subgroup averages, as you have seen in Chapter 1. I illustrate by returning to the course evaluation dataset.
ratings <- foreign::read.dta("TeachingRatings.dta") # lm() with an interaction termlm(course_eval ~ female + minority + female:minority, data = ratings)
# Subgroup averages: how many subgroups are there? with(ratings, tapply(course_eval, list(female, minority), mean))
0 1
0 4.066250 4.092857
1 3.938365 3.736111
# How many observations are within every subgroup? with(ratings, table(female, minority))
minority
female 0 1
0 240 28
1 159 36
In a situation where both \(X_1\) and \(X_2\) are binary, the coefficient of the interaction term is sometimes of direct interest and could be interpreted directly. Let us repeat our predictive comparisons taking into account that both \(X_1\) and \(X_2\) are binary.
The best linear prediction of \(Y\) when \(X_1=0\) and \(X_2=0\) is \(\beta_0^*\).
The best linear prediction of \(Y\) when \(X_1=1\) and \(X_2=0\) is \(\beta_0^*+\beta_1^*\).
When we compare the best linear predictions of \(Y\) for cases where \(X_1=1\) and \(X_2=0\) against cases where \(X_1=0\) and \(X_2=0\), the predicted difference between those cases is \(\beta_1^*\).
In a similar fashion, when we compare the best linear predictions of \(Y\) for cases where \(X_1=0\) and \(X_2=1\) against cases where \(X_1=0\) and \(X_2=0\), the predicted difference between those cases is \(\beta_2^*\).
To obtain a direct interpretation of \(\beta_3^*\) alone, we need to make comparisons of comparisons. Specifically:
Compare the best linear predictions for cases where \(X_1=1\) and \(X_2=1\) against cases where \(X_1=1\) and \(X_2=0\).
Compare the best linear predictions for cases where \(X_1=0\) and \(X_2=1\) against cases where \(X_1=0\) and \(X_2=0\).
The difference between the predicted difference in Item 1 relative to the predicted difference in Item 2 is \(\beta_3^*\).
We can also summarize these comparisons in a tabular format:
\(X_2=0\)
\(X_2=1\)
Difference
\(X_1=0\)
\(\beta_0^*\)
\(\beta_0^*+\beta_2^*\)
\(\beta_2^*\)
\(X_1=1\)
\(\beta_0^*+\beta_1^*\)
\(\beta_0^*+\beta_1^*+\beta_2^*+\beta_3^*\)
\(\beta_2^*+\beta_3^*\)
Difference
\(\beta_1^*\)
\(\beta_1^*+\beta_3^*\)
\(\beta_3^*\)
A reason why this table is of substantial interest in practice is because it is possible to make causal statements using an approach called difference-in-difference or diff-in-diff or DID. In applications using DID, \(X_1\) would represent a policy intervention or a treatment and \(X_2\) would represent a before and after binary regressor.
In its most basic form, the approach uses the same table, but \(\beta_3^*\) can be given a causal interpretation and as you noticed, lm() can be used to recover \(\beta_3^*\). Of course, the table you have just seen cannot be given a causal interpretation directly. As always, you need a causal model.
Interaction terms are very useful but they become unwieldy if you want to include many interactions. Polynomial terms may be thought of as interaction terms too. They are interactions of a regressor with itself. For example, if you want to include a set of interaction terms if you have three regressors (\(X_1, X_2, X_3\)), then you will have terms like \(X_1^2\), \(X_2^2\), \(X_3^2\), \(X_1X_2\), \(X_1X_3\), and \(X_2X_3\)! In fact, it is also possible to have interaction terms which involve the product of three or more regressors, say \(X_1X_2X_3\). However, the computation of the coefficients of these interaction terms may rely on a very small subset of the data. In addition, some of these interactions will not be included by design if some of your regressors are binary (Why?).
2.4 Tying everything together
I now try to tie everything together in this chapter. This chapter essentially looks into multiple linear regression and other related topics.
2.4.1 Algebraic setup
Let \(Y_t\) be the value of the regressand for the \(t\)th observation. Let \[X_t^\prime=(1, X_{1t}, X_{2t}, \ldots X_{kt})\] be the corresponding values of the regressors. There are \(k\) regressors plus a “1”. Let us revisit our algebraic setup before when we used a spreadsheet layout. But this time, we cast everything in terms of matrices:
lm() computes the regression intercept and slopes, and together we call it \[\widehat{\beta}=\left(\widehat{\beta}_0,\widehat{\beta}_1,\ldots,\widehat{\beta}_k\right)^\prime.\] The fitted values are \[\widehat{Y}_t=X_t^\prime\widehat{\beta}=\widehat{\beta}_0+\widehat{\beta}_1X_{1t}+\ldots+\widehat{\beta}_k X_{kt}.\] The residuals are \[\widehat{U}_t=Y_t-\widehat{Y}_t.\]lm() is based on a computationally efficient way of calculating \[\widehat{\beta}=\left(\frac{1}{n}\sum_{t=1}^n X_tX_t^\prime\right)^{-1}\left(\frac{1}{n}\sum_{t=1}^n X_tY_t\right)=\left(X^\prime X\right)^{-1} X^\prime Y. \tag{2.11}\]
As you may have noticed, simply giving you the formula for \(\widehat{\beta}\) to you is probably not going to be useful. In this chapter, I emphasized instead how the case of multiple linear regression is really simple linear regression once you know the Frisch-Waugh-Lovell theorem in Section 2.2.4. Finally, Equation 2.11 will not exist if \(X^\prime X\) is not invertible or if \(X^\prime X\) is singular. You have already seen in Section 2.2.2 examples of situations where singularity can happen. But the more frequent case arising in practice would be numerical instabilities which lead to near singularity of \(X^\prime X\).
2.4.2 Prediction setup
In a similar fashion, we can ask the long-run “order” of the regression coefficients produced by lm() under the fiction we discussed in Chapter 1.
We extend our setup Section 1.3.2 and now predict scalar \(Y\) when you have information about a vector \(X=\left(1,X_{1},\ldots,X_{k}\right)^{\prime}\). What stays the same? What changes? For the best linear predictor, the choice set is now the set of all \(\beta=\left(\beta_{0},\beta_{1},\ldots,\beta_{k}\right)^{\prime}\in\mathbb{R}^{k+1}\) such that the prediction rule has the form \(\beta_{0}+\beta_{1}X_{1}+\cdots+\beta_{k}X_{k}=X^{\prime}\beta\). The properties of the prediction error \(u\) still stay the same (again with minor notation changes).
For the best linear predictor, the system of equations before\[\left(\begin{array}{cc}
1 & \mathbb{E}\left(X_1\right)\\
\mathbb{E}\left(X_1\right) & \mathbb{E}\left(X^{2}_1\right)
\end{array}\right)\left(\begin{array}{c}
\beta_{0}^{*}\\
\beta_{1}^{*}
\end{array}\right) = \left(\begin{array}{c}
\mathbb{E}\left(Y\right)\\
\mathbb{E}\left(X_1Y\right)
\end{array}\right)\] extends to \[\underbrace{\left(\begin{array}{cccc}
1 & \mathbb{E}\left(X_{1}\right) & \cdots & \mathbb{E}\left(X_{k}\right)\\
\mathbb{E}\left(X_{1}\right) & \mathbb{E}\left(X_{1}^{2}\right) & \cdots & \mathbb{E}\left(X_{1}X_{k}\right)\\
\vdots & \vdots & \ddots & \vdots\\
\mathbb{E}\left(X_{k}\right) & \mathbb{E}\left(X_{k}X_{1}\right) & \cdots & \mathbb{E}\left(X_{k}^{2}\right)
\end{array}\right)}_{\mathbb{E}\left(XX^{\prime}\right)}\underbrace{\left(\begin{array}{c}
\beta_{0}^{*}\\
\beta_{1}^{*}\\
\vdots\\
\beta_{k}^{*}
\end{array}\right)}_{\beta^{*}} = \underbrace{\left(\begin{array}{c}
\mathbb{E}\left(Y\right)\\
\mathbb{E}\left(X_{1}Y\right)\\
\vdots\\
\mathbb{E}\left(X_{k}Y\right)
\end{array}\right)}_{\mathbb{E}\left(XY\right)}.\] Thus, \[\beta^{*}=\left[\mathbb{E}\left(XX^{\prime}\right)\right]^{-1}\mathbb{E}\left(XY\right), \tag{2.12}\] provided \(\mathbb{E}\left(XX^{\prime}\right)\) is invertible.
Observe the similarity of Equation 2.11 and Equation 2.12. What you have seen before in Chapter 1 also holds in the more general case where you more than just one regressor. Of course, Equation 2.11 and Equation 2.12 are fundamentally different from each other. But there is a sense in which Equation 2.11 (subject to randomness) behaves like Equation 2.12 (a constant) in the long-run. In symbols, you will see this as \[\widehat{\beta} \overset{p}{\to} \beta^*, \ \ \mathrm{as}\ n\to\infty.\] In words, \(\widehat{\beta}\)converges in probability to \(\beta^*\) as you have more and more observations. There are definitely conditions for convergence in probability to hold. We turn to that next.
2.4.3 The “assumption-lean” version of the linear regression model
As you may recall from Section 1.4.1, we have already made a distinction between linear regression and the linear regression model. Even though we made a distinction, there really is a link between the two. In fact, the most “modern” variant of the linear regression model emphasizes what are the essential elements required to justify the use of lm() for prediction purposes. I am also going to borrow the terminology from Berk et al. (2021) and call this “modern” variant the “assumption-lean” version of the linear regression model. The term “assumption-lean” is to contrast it with the description of the model in older textbooks. There are other variants which include, but are not limited to the classical linear regression model, classical normal linear regression model, correctly specified linear regression model, to enumerate a few of the variants. But the bottom line is that we require much fewer assumptions to justify the usage of lm() in predictive settings.
You actually have encountered most of the essential elements of the “modern” variant of the linear regression model and now I formally write them down:
A1\(\{\left(Y_t, X_t^\prime\right)\}_{t=1}^n\) are observable IID random vectors drawn from the joint distribution \(f_{(X_1,\ldots, X_k, Y)}\left(x_1,\ldots,x_k, y\right)\), where \(\mathbb{E}\left(X_tX_t^\prime\right)\) is invertible.
A2 For all \(t\), we have \(Y_t=X_t^\prime\beta+\varepsilon_t\).
A3\(\varepsilon_t\)’s satisfy \(\mathbb{E}\left(\varepsilon_t\right)=0\) and \(\mathbb{E}\left(X_t\varepsilon_t\right)=0\) for all \(t\).
A1 is an assumption that we have IID random sampling from the joint distribution of the regressand and the regressors. It is possible to weaken IID random sampling to cover time series settings where you expect some dependence of the future on the past. It is also possible to weaken IID random sampling to other more complicated settings like panel data and clustered data.
A2 may be interpreted as the data generating process but it is not strictly necessary especially in light of A3. A2 and A3 both imply that the \(\beta\) in A2 is really \(\beta^*\), the coefficients of the best linear predictor of \(Y\) given the \(X\)’s. \(\beta^*\) is a population parameter of interest we want to learn about. It is definitely possible to focus on just a subset of the entire vector. \(\varepsilon_t\) in A3 is also the error from best linear predictor of \(Y\) given the \(X\)’s.
Of course, we can definitely take all three assumptions as how we think the data for \(Y\) were generated. Pretend that you have IID draws \((X_t^\prime, \varepsilon_t)\) from their joint distribution. Make sure that A3 indeed holds for this joint distribution. Further pretend that \(\beta\) is known. Form the component \(X_t^\prime\beta\) and this to \(\varepsilon_t\) in order to produce \(Y_t\). Afterwards, throw away all the pretenses, i.e., act as if we do not know the joint distribution of \((X_t^\prime, \varepsilon_t)\) and the value of \(\beta\). Our task is to recover \(\beta\), which again is equal to \(\beta^*\) given A3.
To estimate \(\beta^*\), we use the ordinary least squares (OLS) estimator\(\widehat{\beta}\). We can only justify the use of the OLS estimator in an asymptotic setting. In particular, when \(n\to\infty\), it can be shown that:
Theorem 2.1 (Large-sample or asymptotic properties of the OLS estimator) Assume that A1, A2, and A3 hold. Further assume that second moments of the joint distribution is finite. Then we have, as \(n\to\infty\):
The OLS estimator \(\widehat{\beta}\) is consistent for \(\beta^*\), i.e. \[\widehat{\beta} \overset{p}{\to} \beta^*.\]
Further assume that fourth moments of the joint distribution is finite. Then, the joint cumulative distribution function (cdf) of a standardized OLS estimator converges to the joint cdf of the standard multivariate normal distribution. In other words, OLS estimator is asymptotically normal, i.e., \[\sqrt{n}\left(\widehat{\beta}-\beta^*\right)
\overset{d}{\rightarrow} N\left(0,\mathbb{E}\left(X_{t}X_{t}^{\prime}\right)^{-1}\mathbb{E}\left(X_{t}X_{t}^{\prime}\varepsilon_t^2\right)\mathbb{E}\left(X_{t}X_{t}^{\prime}\right)^{-1}\right) \tag{2.13}\]
One thing to notice about the first result from Theorem 2.1 is that you have already seen it before in Chapter 1, at least from Monte Carlo simulations. Another thing to notice is that, strictly speaking, the theorem applies even if \(\widehat{\beta}\) may fail to exist for any specific sample. This may be surprising, but the idea is that we are thinking about more and more observations and what is more important is that \(\beta^*\) actually exist. Without the existence of \(\beta^*\), there is nothing to discuss in the first place. We will discuss the result in Equation 2.13 in the next chapter, as the result is the key to uncertainty quantification.
Finally, if you want to justify the use of lm() in causal settings, then you have to ensure that A2 and A3 form a causal model and that \(\beta^*\) matches the desired causal effect. Typically, you would have to add more assumptions to guarantee both. Without these additional assumptions, the best you could do is settle for a predictive interpretation.
2.4.4 Conditional expectations and linear regression
There is a common thread tying nonlinear transformations of the regressand discussed in Section 2.2.1.2 and actually applied in our motivating example and the inclusion of polynomial terms discussed in Section 2.3.2. What ties these topics together is nonlinearity. But as you have seen before, there are many senses in which nonlinearities enter a model.
Equation 2.10 introduces a new object called a conditional expectation. Furthermore, Equation 2.10 also suggests that the best linear predictor involving polynomial terms of increasing degree give enough flexibility to approximate a conditional expectation.
Let us return to our prediction task in Section 1.3.2. Suppose we have two random variables \(X_{1}\) and \(Y\), which follow a joint distribution \(f_{X_{1},Y}\left(x_{1},y\right)\). Suppose you draw a unit at random from the subpopulation of units with \(X_{1}=x_{1}\). Your task is to predict this unit’s \(Y\). How do we accomplish this task optimally? In Section 1.3.2, we specify a linear prediction rule of the form \(\beta_0+\beta_1 X_1\). We now consider a prediction rule of the form \(g\left(X_1\right)\) instead of \(\beta_{0}+\beta_{1}X_{1}\). The task is now to find the unique solution to the following optimization problem: \[\min_{g}\mathbb{E}\left[\left(Y-g\left(X_1\right)\right)^{2}\right]. \tag{2.14}\] It is hard to use calculus directly here, because we are looking for optimal functions \(g\) rather than just optimal coefficients for \(\beta_0\) and \(\beta_1\).
To make progress, it may be good to think about how to improve the best linear predictor \(\beta_0^*+\beta_1^* X_1\). You already know that \(\mathbb{E}\left(U\right)=0\) and \(\mathbb{E}\left(UX_1\right)=0\) if \(U\) is the error from using the best linear predictor \(\beta_0^*+\beta_1^* X_1\). As a result, \(\mathsf{Cov}\left(X_1,U\right)=0\).
\(\mathsf{Cov}\left(X_1,U\right)=0\) really means that there are no more linear functions of \(X_1\) left behind as “information” about \(X_1\) in the error \(U\). If we want to improve on the best linear predictor, we may want to ensure that no other functions (not just linear ones) of \(X_1\) are left behind in \(U\). In effect, you would have extracted completely all “information” about \(X_1\) useful for prediction. Therefore, we may want to find \(g\left(X_1\right)\) so that \(\mathsf{Cov}\left(h\left(X_1\right),U\right)=0\) for all functions \(h\). The preceding argument motivates the following definition:
Definition 2.1 (Conditional expectation function) The conditional expectation function (CEF)\(\mathbb{E}\left(Y|X_1\right)\) of a random variable \(Y\) is defined as a function of \(X_1\) which satisfies \[\mathbb{E}\left[\left(Y-\mathbb{E}\left(Y|X_1\right)\right)h\left(X_1\right)\right]=0\] for any function of \(h\left(X_1\right)\) of \(X_1\).
I claim that the conditional expectation \(\mathbb{E}\left(Y|X_1\right)\) solves the minimization problem in Equation 2.14.17 In other words, \(\mathbb{E}\left(Y|X_1\right)\) is the best predictor of \(Y\) given \(X_1\).
We can write the MSE of any other function \(g\) of \(X_1\) as \[\begin{aligned}\mathbb{E}\left[\left(Y-g\left(X_1\right)\right)^{2}\right] & =\underbrace{\mathbb{E}\left[\left(Y-\mathbb{E}\left(Y|X_1\right)\right)^{2}\right]}_{\mathsf{(a)}}+\underbrace{\mathbb{E}\left[\left(\mathbb{E}\left(Y|X_1\right)-g\left(X_1\right)\right)^{2}\right]}_{\mathsf{(b)}}\\
& +2\underbrace{\mathbb{E}\left[\left(Y-\mathbb{E}\left(Y|X_1\right)\right)\left(\mathbb{E}\left(Y|X_1\right)-g\left(X_1\right)\right)\right]}_{\mathsf{(c)}}.
\end{aligned}\]
First, observe that \(\mathsf{(a)}\) can no longer be minimized reagrdless of which \(g\) you choose. Therefore, \(\mathsf{(a)}\) is sometimes called the irreducible risk in machine learning contexts.
Next, observe that \(g\) shows up in \(\mathsf{(b)}\) and \(\mathsf{(c)}\). For \(\mathsf{(c)}\), observe that if we took \(h\left(X_1\right)=\mathbb{E}\left(Y|X_1\right)-g\left(X_1\right)\) in the definition of the conditional expectation, then \(\mathsf{(c)}\) is equal to zero, regardless of the choice for \(g\).
What is left is \(\mathsf{(b)}\). The only way to make \(\mathsf{(b)}\) small by the choice of \(g\) is to choose \(g\left(X_1\right) = \mathbb{E}\left(Y|X_1\right)\). Therefore, the optimal \(g\) which minimizes MSE has to be the conditional expectation \(\mathbb{E}\left(Y|X_1\right)\).
It is possible to extend the idea to the best prediction of \(Y\) given \(X_1, \ldots, X_k\) paralleling what we did for the best linear prediction of \(Y\) given \(X_1, \ldots, X_k\).
If linear regression recovers the coefficients of the best linear predictor, a natural question to ask is under what circumstances can linear regression recover the best predictor? Furthermore, if these circumstances are not satisfied, what alternative methods aside from linear regression can be used to recover the best predictor?
The first question can be immediately answered simply by looking to a strengthening of assumption A3 in the “assumption-lean” version of the linear regression model. The strengthening is inspired by Definition 2.1. Thus, we have the so-called correctly specified linear regression model, i.e.
A1\(\{\left(Y_t, X_t^\prime\right)\}_{t=1}^n\) are observable IID random vectors drawn from the joint distribution \(f_{(X_1,\ldots, X_k, Y)}\left(x_1,\ldots,x_k, y\right)\), where \(\mathbb{E}\left(X_tX_t^\prime\right)\) is invertible.
A2 For all \(t\), we have \(Y_t=X_t^\prime\beta+\varepsilon_t\).
A3’\(\varepsilon_t\)’s satisfy \(\mathbb{E}\left(h\left(X_t\right)\varepsilon_t\right)=0\) for all \(t\) and for all functions \(h\).
A sufficient condition for A3’ is the zero conditional mean assumption for \(\varepsilon_t\), i.e. \[\mathbb{E}\left(\varepsilon_t|X_t\right)=0.\] Clearly, A3’ implies A3. Therefore, \(\beta\) still carries the meaning of \(\beta^*\), the coefficients of the best linear predictor. But the difference now is that the linear prediction rule is actually correctly chosen or specified. In other words, the conditional expectation, which is the best predictor, coincides with \(\beta_0^*+\beta_1^* X_1\), which is the best linear predictor. Because of these, we will introduce new notation \(\beta^o\) to be \(\beta^*\) in the correctly specified case.
Theorem 2.2 (Large-sample or asymptotic properties of the OLS estimator under correct specification) Assume that A1, A2, and A3’ hold. Further assume that second moments of the joint distribution is finite. Then we have, as \(n\to\infty\):
The OLS estimator \(\widehat{\beta}\) is consistent for \(\beta^o\), i.e. \[\widehat{\beta} \overset{p}{\to} \beta^o.\]
Further assume that fourth moments of the joint distribution is finite. Then, the joint cumulative distribution function (cdf) of a standardized OLS estimator converges to the joint cdf of the standard multivariate normal distribution. In other words, OLS estimator is asymptotically normal, i.e., \[\sqrt{n}\left(\widehat{\beta}-\beta^o\right)
\overset{d}{\rightarrow} N\left(0,\mathbb{E}\left(X_{t}X_{t}^{\prime}\right)^{-1}\mathbb{E}\left(X_{t}X_{t}^{\prime}\varepsilon_t^2\right)\mathbb{E}\left(X_{t}X_{t}^{\prime}\right)^{-1}\right) \tag{2.15}\]
What you may have noticed is that Theorem 2.2 and Theorem 2.1 look remarkably similar. But they have different content and guarantees about the behavior of \(\widehat{\beta}\). Theorem 2.2 definitely relies on stronger assumptions that Theorem 2.1. Most econometrics textbooks actually start with a correctly specified linear regression model. But it is extremely rare for the correctly specified linear regression model to hold in practice, unless otherwise demonstrated by proof or a convincing argument.
2.4.5 Saturated models
A very relevant question is to determine whether there are settings where the correctly specified linear regression model would be expected to hold. The most relevant and realistic setting encountered in practice is the case when the \(X\)’s are all binary, regardless of whether \(Y\) is continuous or discrete. We refer to this case as the “saturated model”.
For simplicity, suppose \(X\) takes on only two values, 0 and 1. Therefore, we have \[\mathbb{E}\left(Y|X=0\right)=\pi_{0},\ \mathbb{E}\left(Y|X=1\right)=\pi_{1}.\] In short, \[\mathbb{E}\left(Y|X\right)=\pi_{0}+\left(\pi_{1}-\pi_{0}\right)X.\] So, you can set \(\beta_{0}^{*}=\pi_{0}\) and \(\beta_{1}^{*}=\pi_{1}-\pi_{0}\). You will then conclude that the conditional expectation matches the best linear predictor.
In a situation where \(X\) takes on three values, 0, 1, and 2, we have: \[\mathbb{E}\left(Y|X=0\right)=\pi_{0},\ \ \mathbb{E}\left(Y|X=1\right)=\pi_{1},\ \ \mathbb{E}\left(Y|X=2\right)=\pi_{2}.\] Define \[X_{1}=\begin{cases}
1 & \mathrm{if}\;X=1\\
0 & \mathrm{otherwise}
\end{cases},\quad X_{2}=\begin{cases}
1 & \mathrm{if}\;X=2\\
0 & \mathrm{otherwise}
\end{cases}.\] In short, \[\mathbb{E}\left(Y|X_{1},X_{2}\right)=\pi_{0}+\left(\pi_{1}-\pi_{0}\right)X_{1}+\left(\pi_{2}-\pi_{0}\right)X_{2}.\] Observe that the conditional expectation is actually the best linear predictor.
2.5 Revisiting MRW, focusing on estimation
The R code below reproduces the first column of Table I of MRW.
We did not exactly reproduce the estimates of the intercept found in Table I, yet all the slope estimates are the same. Based on Section 2.2.1.1, we can conclude that it may be possible that a linear transformation was applied to the regressors. In fact, the issue is that the measures of saving rate and population growth in the data have to be converted to decimals rather than percentage points. Once this is accounted for, we can reproduce the estimates for the intercept.
# Redefine the regressorsmrw$logs <-log(mrw$inv/100)mrw$logpop <-log(mrw$pop/100+0.05)# Apply OLS to non-oil sampleresults <-lm(logy85pc ~ logs + logpop, data = mrw, subset = (n==1))coef(results)
What econometric theory justifies the use of lm() to estimate \(\beta_0,\beta_1, \beta_2\) for the model \[\log y^{*} = \beta_0+\beta_1\log s+\beta_2\log\left(n_t+g+\delta\right)+\varepsilon\] under the identifying assumption that \(\varepsilon\) is independent of \(s\) and \(n\)?
Theorem 2.1 and Theorem 2.2 are the key results which will help us justify the use of lm(). Consider the following mapping of MRW to the notation of the theorems: \[\begin{eqnarray*} \log y^{*}_t & \rightarrow & Y_t \\ \left(1, \log s_t, \log(n_t+g+\delta)\right) &\rightarrow& X_t^\prime \\ (\beta_0,\beta_1,\beta_2)^\prime &\rightarrow& \beta\\ \varepsilon_t &\rightarrow& \varepsilon_t.\end{eqnarray*}\] If we assume that we have IID random sampling of \((Y_t, X_t^\prime)\) for \(t=1,\ldots,n\), then A1 in both Theorem 2.1 and Theorem 2.2 is satisfied. We also have A2 in both Theorem 2.1 and Theorem 2.2. The identifying assumption of MRW implies A3 for Theorem 2.1 and A3’ for Theorem 2.2.
Although both sets of assumptions required to justify the use of the OLS estimator are satisfied, you have to wonder why MRW impose a stronger assumption. The answer to this question leads us to unresolved questions regarding nonlinear transformations of the regressand.
2.6 Nonlinear transformations of the regressand
2.6.1 Only the regressand is logged
Consider the following simplified setup. Let \[\log Y =\beta_0+\beta_1 X + \varepsilon.\] A big issue rests on making interpretations and statements based on the original scale of \(Y\). That means we want to interpret results based on \(Y\) rather than the logarithm of \(Y\). We can write \[\begin{eqnarray*}Y &=& \exp\left(\beta_0+\beta_1 X + \varepsilon\right) \\ &=& \exp\left(\beta_0+\beta_1 X\right)\exp\varepsilon.\end{eqnarray*}\] Now, we compute \(\mathbb{E}\left(Y|X\right)\): \[\mathbb{E}\left(Y|X\right)=\exp\left(\beta_0+\beta_1 X\right)\mathbb{E}\left(\exp\varepsilon|X\right).\] How can we make progress in interpreting \(\beta_1\)? We are going to make an assumption similar to MRW. Assume that \(\varepsilon\) is independent of \(X\). This assumption implies that \(\mathbb{E}\left(\exp\varepsilon|X\right)=\mathbb{E}\left(\exp\varepsilon\right)\)
The best prediction of \(Y\) given \(X=x\) is \(\exp\left(\beta_0+\beta_1 x\right)\mathbb{E}\left(\exp\varepsilon\right)\).
The best prediction of \(Y\) given \(X=x+\Delta x\) is \(\exp\left(\beta_0+\beta_1 (x+\Delta x)\right)\mathbb{E}\left(\exp\varepsilon\right)\).
The predicted difference in \(Y\) is given by \[\begin{eqnarray*} && \mathbb{E}\left(Y|X=x+\Delta x\right)-\mathbb{E}\left(Y|X=x\right) \\
&=& \exp\left(\beta_0+\beta_1 x\right)\left[\exp(\beta_1 \Delta x)-1\right]\mathbb{E}\left(\exp\varepsilon\right). \end{eqnarray*}\]
At this stage, it becomes clearer that the predicted difference in \(Y\) depends on features of the distribution of the unobserved \(\varepsilon\). To make further progress, we need to consider the predicted relative difference in \(Y\) instead, i.e., \[\begin{eqnarray*} && \frac{\mathbb{E}\left(Y|X=x+\Delta x\right)-\mathbb{E}\left(Y|X=x\right)}{\mathbb{E}\left(Y|X=x\right)} \\
&=& \frac{\exp\left(\beta_0+\beta_1 x\right)\left[\exp(\beta_1 \Delta x)-1\right]\mathbb{E}\left(\exp\varepsilon\right)}{\exp\left(\beta_0+\beta_1 x\right)\mathbb{E}\left(\exp\varepsilon\right)} \\
&=& \exp(\beta_1 \Delta x)-1. \end{eqnarray*}\] Observe that the predicted relative difference in \(Y\) does not depend on unobservables anymore and depends only on \(\beta_1\) and the contemplated difference \(\Delta x\).
The preceding arguments point to the crucial requirement where \(\varepsilon\) is independent of \(X\) so that you will obtain a predicted relative difference interpretation for \(\beta_1\).
2.6.2 Both regressand and regressor are logged
When both the regressand and the regressor are logged, there is a natural tendency to interpret the regression coefficients as elasticities. Unfortunately, this interpretation is only approximately correct in the best case and actually incorrect in the worst case.
Consider another simplified situation where \(Z=\alpha_{1}W^{\alpha_{2}}\eta\) and \(\mathbb{E}\left(\eta|W\right)=1\). As a result, \(\mathbb{E}\left(Z|W\right)=\alpha_{1}W^{\alpha_{2}}\). But many have tried to apply log-linearization to \(Z=\alpha_{1}W^{\alpha_{2}}\eta\) in order to get it in a linear regression format, i.e., \(\log Z=\log\alpha_{1}+\alpha_{2}\log W+\log\eta\). The parameter of interest is \(\alpha_{2}\) and is usually interpreted as an elasticity.
To show why \(\alpha_{2}\) may be interpreted as an elasticity, recall the definition of elasticity and apply it to \(\mathbb{E}\left(Z|W\right)\), i.e., \[\log\mathbb{E}\left(Z|W\right) = \log\alpha_{1}+\alpha_{2}\log W
\Rightarrow\dfrac{\partial\log\mathbb{E}\left(Z|W\right)}{\partial\log W} = \alpha_{2}.\] But in the log-linearization, we have \[\begin{aligned}\mathbb{E}\left(\log Z|W\right) = \log\alpha_{1}+\alpha_{2}\log W+\mathbb{E}\left(\log\eta|W\right) \\
\Rightarrow\dfrac{\partial\mathbb{E}\left(\log Z|W\right)}{\partial\log W} = \alpha_{2}+\dfrac{\partial\mathbb{E}\left(\log\eta|W\right)}{\partial\log W}=\alpha_{2}+W\cdot\dfrac{\partial\mathbb{E}\left(\log\eta|W\right)}{\partial W}\end{aligned}\]
Therefore, the only time that the log-linearization allows you to recover the correct elasticity \(\alpha_{2}\) is when \(\mathbb{E}\left(\log\eta|W\right)\) is not a function of \(W\).
Take note that even if \(\mathbb{E}\left(\eta|W\right)=1\), we could not say anything exact about \(\mathbb{E}\left(\log\eta|W\right)\). In fact, \(\mathbb{E}\left(\eta|W\right)=1\) does imply \(\log\mathbb{E}\left(\eta|W\right)=0\) but it does not imply \(\mathbb{E}\left(\log\eta|W\right)=0\).18
Full independence of \(\eta\) and \(W\) would guarantee that a log-linearization would recover the correct elasticity \(\alpha_2\).
We now modify the most crucial assumption to accommodate what we have observed about the effect of nonlinear transformations on the regressand. The preceding discussion should already be enough to convince you why MRW impose a stronger assumption like full independence. As a result, we now have A3’’:
A1\(\{\left(Y_t, X_t^\prime\right)\}_{t=1}^n\) are observable IID random vectors drawn from the joint distribution \(f_{(X_1,\ldots, X_k, Y)}\left(x_1,\ldots,x_k, y\right)\), where \(\mathbb{E}\left(X_tX_t^\prime\right)\) is invertible.
A2 For all \(t\), we have \(Y_t=X_t^\prime\beta+\varepsilon_t\).
A3’’\(\varepsilon_t\) is independent of \(X_t\).
Under additional conditions with respect to the existence of moments, A3’’ implies A3’. You already know that A3’ implies A3. Therefore, \(\beta\) still carries the meaning of \(\beta^*\), the coefficients of the best linear predictor. We also have that the linear prediction rule is actually correctly chosen or specified. In other words, the conditional expectation, which is the best predictor, coincides with \(\beta_0^*+\beta_1^* X_1\), which is the best linear predictor. But more importantly, the meaning of \(\beta^o\) also changes, so we will introduce new notation \(\beta^{f}\) to be \(\beta^o\) in the full independence case.
We now have a new theorem which justifies the use of the OLS estimator in the full independence case. Compare Equation 2.15 and Equation 2.16. Observe that there is a simplification obtained in the full independence case. We will discuss this further in the next chapter.
Theorem 2.3 (Large-sample or asymptotic properties of the OLS estimator under full independence) Assume that A1, A2, and A3’’ hold. Further assume that second moments of the joint distribution is finite. Then we have, as \(n\to\infty\):
The OLS estimator \(\widehat{\beta}\) is consistent for \(\beta^{f}\), i.e. \[\widehat{\beta} \overset{p}{\to} \beta^{f}.\]
Further assume that fourth moments of the joint distribution is finite. Then, the joint cumulative distribution function (cdf) of a standardized OLS estimator converges to the joint cdf of the standard multivariate normal distribution. In other words, OLS estimator is asymptotically normal, i.e., \[\sqrt{n}\left(\widehat{\beta}-\beta^{f}\right)
\overset{d}{\rightarrow} N\left(0,\mathbb{E}\left(\varepsilon_t^2\right)\mathbb{E}\left(X_{t}X_{t}^{\prime}\right)^{-1}\right) \tag{2.16}\]
Berk, Richard, Andreas Buja, Lawrence Brown, Edward George, Arun Kumar Kuchibhotla, Weijie Su, and Linda Zhao. 2021. “Assumption Lean Regression.”The American Statistician 75 (1): 76–84. https://doi.org/10.1080/00031305.2019.1592781.
Bernanke, Ben S., and Refet S. Gürkaynak. 2002. “Is Growth Exogenous? Taking Mankiw, Romer, and Weil Seriously.” In NBER Macroeconomics Annual 2001, Volume 16, 11–72. MIT Press. http://www.nber.org/chapters/c11063.
Mankiw, N. G., David Romer, and David Weil. 1992. “A Contribution to the Empirics of Economic Growth.”Quarterly Journal of Economics 107 (May): 407–37.
Silva, J. M. C. Santos, and Silvana Tenreyro. 2006. “The Log of Gravity.”The Review of Economics and Statistics 88 (4): 641–58. https://doi.org/10.1162/rest.88.4.641.
You may download a legitimate copy of MRW from Mankiw’s website for the paper here. You have to learn how to read papers and this paper is a pedagogically useful starting point for any beginner in econometrics.↩︎
The course evaluation data does feature a transformed variable which is the standardized beauty rating.↩︎
Pay attention to scientific notation in R. We see here 0.00017 rather than \(1.7\times 10^{-4}\). R sometimes displays 0.00017 as 1.7e-4. I chose 0.00017 so I formatted the result so that it will not be displayed in scientific notation. Use format(0.00017, scientific = FALSE) to make what I described possible.↩︎
I purposefully omitted this topic because it gets more attention than it deserves. It is not a useless measure but there is tendency for those exposed to econometrics to overly pay attention to this measure.↩︎
The usage of this term is more technical than the usual usage in conversational English. I think the term “factor” comes from the days of agricultural experimentation.↩︎
It does not have to particularly be \(X_1\). You could include polynomial terms involving \(X_2\).↩︎
One convergence concept encountered in probability and statistics is the concept of convergence in quadratic mean or mean squared error convergence.↩︎
Out-of-sample data are sometimes called test sets in machine learning contexts. The data you actually use are sometimes called training sets in machine learning contexts. For the moment, we have emphasized predictive differences.↩︎
As of writing, I am unable to provide a more detailed discussion about the origins of the term. For now, I recall that this term is widely used in the analysis of experimental data where the idea is that the effect of a factor influencing experimental outcomes can have an additional effect when combined with another factor. The experimenter should be able to directly manipulate these factors.↩︎
This expression may feel familiar to those who encountered conic sections in analytic geometry. For example, the equation of a circle could be cast in the given form.↩︎
There are technical conditions which I dropped here.↩︎
As an approximation, we can use a Taylor series argument to obtain \[\mathbb{E}\left(\log\eta|W\right)\approx\log\mathbb{E}\left(\eta|W\right)-\dfrac{\mathsf{V}\left(\eta|W\right)}{2\mathbb{E}\left(\eta|W\right)^{2}}=-\dfrac{1}{2}\mathsf{V}\left(\eta|W\right).\]↩︎