In this chapter, I will introduce to you a technique called linear regression by letting you see it as a software command first. The motivation for proceeding in this manner is because a lot of students and/or practitioners pick up techniques not necessarily by learning the theory first but from using software in applications directly.
At this stage, you may or may not have a question in mind for which you find yourself wanting to apply linear regression. To distinguish your use of software from other users, you may want to try to understand what the software is doing in some special cases.
In this chapter, I also incorporate R directly so that you can jump in right away and learn as you go. The style is not in the form of a tutorial, as there are other tutorial resources available.
1.1 As a summary
This subsection is directly based on Pua (2023) which was written in honor of Dr. Tereso Tullao, Jr.
1.1.1 Jumping into linear regressions in a software package
At their core, linear regressions are not fundamentally different from usual summaries of the data. Let me illustrate using an extract1 by Stock and Watson (2012) from a course evaluation dataset collected by Hamermesh and Parker (2005).
A typical2 dataset may be thought of as a spreadsheet with each column representing a variable being measured and with each row representing a unit of analysis which may or may not contain a record of each variable being measured.
Let us try getting a preview of what the data looks like. First, we load the data which is in Stata format3 using the command read.dta() from the foreign package. Second, we can obtain a preview of the dataset using the built-in R function head(). By default, head() shows the first 6 observations on all the variables. We can also find out how many observations there are in the dataset.
Pay attention to the names of the variables and the plausible range of values of these variables. The names of the variables are in a vector of strings and strings are enclosed in quotation marks.
We will focus on two variables: course_eval and female. Each row corresponds to a unit of analysis which in this case is the course given by an instructor. Course evaluations (course_eval) are on a scale of 1 to 5 and the sex of the instructor (female) is coded as 1 is the instructor of course is female and 0 if male.4
Because we are going to focus on these two variables, we can also do something similar when using head():
We see some new things such as [, ], and c(). [ and ] primarily extracts elements. c() creates a vector by putting together elements of the same type together.
With these two variables in mind along with the unit of analysis, a natural starting point is to look at the overall average course evaluation and the average course evaluation for males and for females.
There are now three new built-in R functions: mean(), tapply(), with(). mean() should be straightforward but does have its quirks especially when you have missing data. tapply() is typically useful in cases where you apply a function to subgroups.
with(ratings, mean(course_eval))
[1] 3.998272
with(ratings, tapply(course_eval, female, mean))
0 1
4.069030 3.901026
with() is useful in maintaining some readability of the code. It serves to emphasize that when we refer to variable names in functions, we may have either use with() or point to them5. The latter code is a bit messy:
mean(ratings$course_eval)
[1] 3.998272
tapply(ratings$course_eval, ratings$female, mean)
0 1
4.069030 3.901026
The first number is the overall average, the second number is the average of the course evaluations when female is equal to 0 (meaning the instructor is male), and the third number is the average of the course evaluations for females. How are linear regressions connected with these summaries?
I will now compute three sets of linear regressions using the built-in R function lm(). Below you may find the code and a table presenting the results.
reg1 <-lm(course_eval ~1, data = ratings)# reg2 can also be lm(course_eval ~ female, data = ratings)reg2 <-lm(course_eval ~1+ female, data = ratings) stargazer::stargazer(reg1, reg2, type ="text", style ="aer", report ="vc", omit.stat ="all", no.space =FALSE,column.labels =c("reg1", "reg2"), omit.table.layout ="n", model.numbers =FALSE)
Notice how the numbers reported in the table and the preceding result are tied together. reg1 is the linear regression of course evaluations on an intercept (coded 1, which is a column of ones if you imagine a spreadsheet) and the software output reproduces the overall average of course evaluation. reg2 is the linear regression of course evaluations on the sex of the instructor, including an intercept. The reported constant reproduces the average of the course evaluations for male instructors. The reported coefficient for female is actually a difference of means. It compares the average for females (3.901) to the average of males (4.069) in a particular way: (3.901 - 4.069 = -0.168). In other words, the average course evaluation of female instructors is about 0.17 points lower than the average course evaluation of male instructors.6
Observe that both sets of linear regressions reg1 and reg2 are compatible with each other. At this stage, there really is no reason to prefer one linear regression over the other, unless we have some specific questions we want to answer or we bring in either our own views of the world, some assumptions, perhaps our biases, and so on.
1.1.2 Some algebra for simple linear regression
At this stage, I hope you are curious why you have different ways of computing the same objects – the overall average and the subgroup averages. I also hope you are curious as to the origins of these numbers. You know that calculating averages is just a matter of summing up values and then dividing by the total number of values.
Let \(t\) index the observation number and that there are \(n\) observations. Let \(Y_1,\ldots,Y_n\) be measurements of \(Y\) for each observation. The overall average is then \[\overline{Y}=\frac{1}{n}\sum_{t=1}^n Y_t\] What may not be very familiar is how to write down expressions for subgroup averages.
The idea is to introduce an indicator variable. Let \(X_{1t}\) take on two values 0 and 1, where \(X_{1t}=1\) indicates the presence of a characteristic and \(X_{1t}=0\) indicates its absence. The average \(Y\) for the subgroup where \(X_{1}=1\) is then \[\frac{\frac{1}{n}\sum_{t=1}^n Y_t X_{1t}}{\frac{1}{n}\sum_{t=1}^n X_{1t}}\] How would you write down the expression for the average \(Y\) for the subgroup where \(X_{1}=0\)?
If we have these expressions which allow us to directly calculate averages from different cuts of the data, then why even bother learning linear regressions? One reason is that we are studying special cases. For example, think about what happens when there are multiple subgroups.
So what is special about the reported results from lm()? What was reported in reg1 is \(\widetilde{\beta}_0=\overline{Y}\). But \(\overline{Y}\) can be obtained as a solution to the following minimization problem (which is sometimes called a least squares problem): \[\min_{\widetilde{\beta}_0} \frac{1}{n}\sum_{t=1}^n \left(Y_t-\widetilde{\beta}_0 \times 1\right)^2 \tag{1.1}\]
In a somewhat similar fashion for reg2, \(\left(\widehat{\beta}_0, \widehat{\beta}_1\right)\) can be obtained as a solution to the following minimization problem: \[\min_{\left(\widehat{\beta}_0, \widehat{\beta}_1\right)} \frac{1}{n}\sum_{t=1}^n \left(Y_t-\widehat{\beta}_0 \times 1-\widehat{\beta}_1\times X_{1t}\right)^2 \tag{1.2}\]
Take note that R does not literally solves a minimization problem every time you invoke lm(). It does something else from a computational point of view. If we have time, we will explore this aspect. But the minimization problems are more from a theoretical or analytical point of view. You can apply some calculus to find that \(\widetilde{\beta}_0=\overline{Y}\), \(\widehat{\beta}_0=\overline{Y}-\widehat{\beta}_1\overline{X}_1\), and \[\widehat{\beta}_1=\frac{\displaystyle\sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)\left(Y_{t}-\overline{Y}\right)}{\displaystyle\sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)^2} = \frac{\displaystyle\sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)Y_{t}}{\displaystyle\sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)^2} \tag{1.3}\]
From the point of view of using R, \(\widetilde{\beta}_0\), \(\left(\widehat{\beta}_0, \widehat{\beta}_1\right)\) are coefficients of the linear regressions reg1 and reg2:
coef(reg1)
(Intercept)
3.998272
coef(reg2)
(Intercept) female
4.0690299 -0.1680042
But it is not very obvious how, for instance, \(\widehat{\beta}_1\) would be a difference of two subgroup averages in our special case. We have to work this detail out as an opportunity to review summation notation and how to incorporate the special cases.
Finally, there are two objects which are by-products of lm(): the fitted values and the residuals for every observation. The fitted values for reg1 are calculated as \(\widetilde{Y}_t=\widetilde{\beta}_0\). The fitted values for reg2 are calculated as \(\widehat{Y}_t=\widehat{\beta}_0+\widehat{\beta}_1 X_{1t}\). The difference between the actual value and the fitted value is called the residual. For reg1, it will be \(Y_t-\widetilde{Y}_t=Y_t-\widetilde{\beta}_0\). For reg2, it will be \(Y_t-\widehat{Y}_t = Y_t-\widehat{\beta}_0-\widehat{\beta}_1 X_{1t}\).
We can do the calculations directly using built-in functions fitted() and residuals(). But both these functions are expecting results from an lm() calculation.
Observe that whether or not we look at reg1 or reg2, we have:
The average of the fitted values is equal to the average of the actual values of \(Y\).
The average of the residuals is equal to zero.
The correlation between \(X_1\) and the residuals is zero.
The correlation between the fitted values and the residuals is zero.
The variance of the values of \(Y\) is a sum of the variance of the fitted values and the variance of the residuals.
We can demonstrate both these points directly using algebra.
1.1.3 Visualizing a simple linear regression
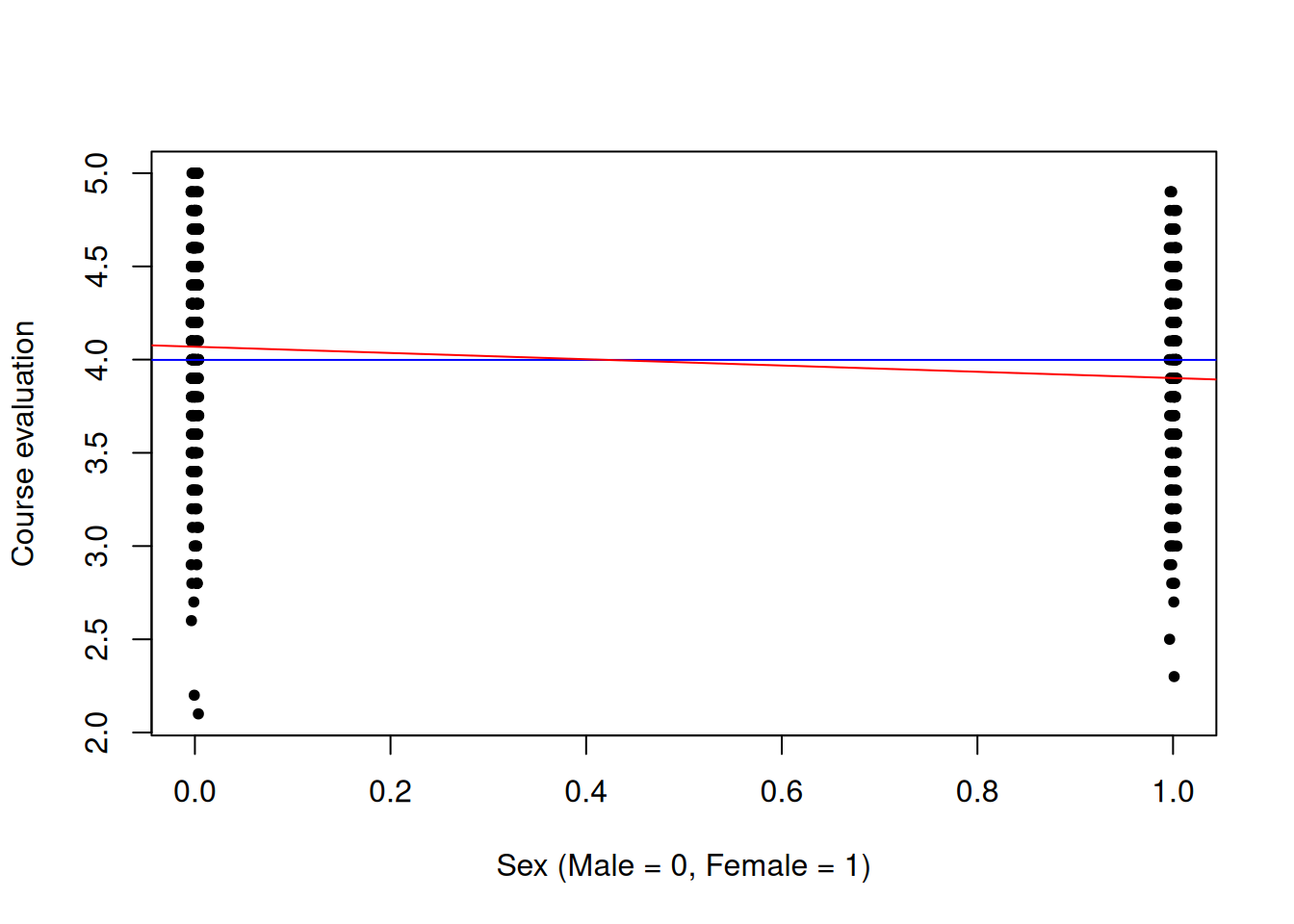
I now present a scatterplot to give a picture of what is happening. I will be plotting on a two-dimensional plane the points \(\left(X_{11}, Y_1\right), \left(X_{12}, Y_2\right), \ldots, \left(X_{1n},Y_n\right)\). The blue line is a visualization of the linear regression reg1. The red line is a visualization of the linear regression reg2.
with(ratings, plot(jitter(female, factor =0.02), course_eval, xlab ="Sex (Male = 0, Female = 1)", ylab ="Course evaluation", pch =20))# I should change this to a color-blind friendly palette. abline(reg1, col ="blue")abline(reg2, col ="red")
For convenience, let \(t\) index the observation number. We also let \(Y_t\) be the evaluation of the \(t\)th course and \(X_{1t}\) be the sex of the instructor teaching the \(t\)th course. Linear regressions reg1 and reg2 may be represented as equations. The equation of the blue line is given by: \[\widetilde{Y}_t =3.998\] In contrast, the equation of the red line is given by:
\[\widehat{Y}_t = 4.069-0.168*X_{1t}\]
The notations \(\widetilde{Y}_t\) and \(\widehat{Y}_t\) serve to distinguish the actual value \(Y_t\) of course evaluations from a value of \(Y\) calculated based on reg1 or reg2.
1.1.4 Short and long regressions
There is another common theme shared by these results. Refer to reg1 and reg2 once more. In both results, you have two different intercepts with different interpretations but are mutually compatible descriptions of the data.
To dig deeper into how they are algebraically related, we look at a simpler version of the setup of short and long regressions. reg1 is the short regression, while reg2 is the long regression. The terminology arises from the longer list of regressors in reg2, namely 1 and female, compared to reg1 (which is just 1). Let \(\widetilde{Y}_t = \widetilde{\beta}_0\) be the short regression, and \(\widehat{Y}_t = \widehat{\beta}_0+ \widehat{\beta}_1 X_{1t}\) be the long regression. We obtain \(\widetilde{\beta}_0\), \(\widehat{\beta}_0\), and \(\widehat{\beta}_1\) from an appropriate use of lm(). Note further that \(\widetilde{Y}_t\) and \(\widehat{Y}_t\) are different fitted values. How is \(\widehat{\beta}_0\) related to \(\widetilde{\beta}_0\) algebraically?
We can obtain a linear regression of \(X_{1}\) on a column of ones, i.e., \(\widehat{X}_{1t}=\widehat{\delta}_0\). Here we obtain \(\widehat{\delta}_0\) from an appropriate use of lm(). Next, \(X_{1t}\) differs from the fitted value \(\widehat{X}_{1t}\) by a residual. Therefore,
In the second equality, we used the property that residuals should sum up to zero. In the third equality, we used the property that the average of the fitted values is equal to the average of the actual values of \(Y\). Similarly, we also have
Since the average of the actual values of \(Y\) is a unique value, then we must have \[\widetilde{\beta}_0= \widehat{\beta}_0+\widehat{\beta}_1 \widehat{\delta}_0\]
This algebraic relationship has a very neat (perhaps surprising to some) interpretation in our course evaluation example:
\[\begin{eqnarray*}
\text{Overall mean} &=& \underset{\widehat{\beta}_0}{\text{Average for males}} \\
&& + \ \underset{\widehat{\beta}_1}{\left(\text{Average for females}\ - \ \text{Average for males}\right)} \ * \ \underset{\widehat{\delta}_0}{\text{Proportion of females}} \\
&=& \text{Proportion of females} \ * \ \text{Average for females}\\
&& + \ \text{Proportion of males} \ * \ \text{Average for males}
\end{eqnarray*}\]
But, more importantly, this algebraic relationship tells us that different sets of linear regressions are connected to each other in a very particular way.
1.2 A detour: Jumping into Monte Carlo simulations
In this detour, you will be exposed to perhaps your first Monte Carlo simulation. A Monte Carlo simulation allows you to generate a large number of artificial datasets obeying some design or specification. After generating these artificial datasets, we apply lm() and explore its behavior when applied repeatedly across these datasets.
1.2.1 Behavior of results from lm()
What follows is an implementation of a Monte Carlo simulation in R. I left the code unevaluated, so that you can evaluate it on your own computer. The code is based on a data generating process (or generative process) to mimic some of the features of the special cases we have been studying. I focus on a continuous \(Y\) and a binary \(X_1\) and I look into the behavior of a similar command as lm(course_eval ~ 1 + female).
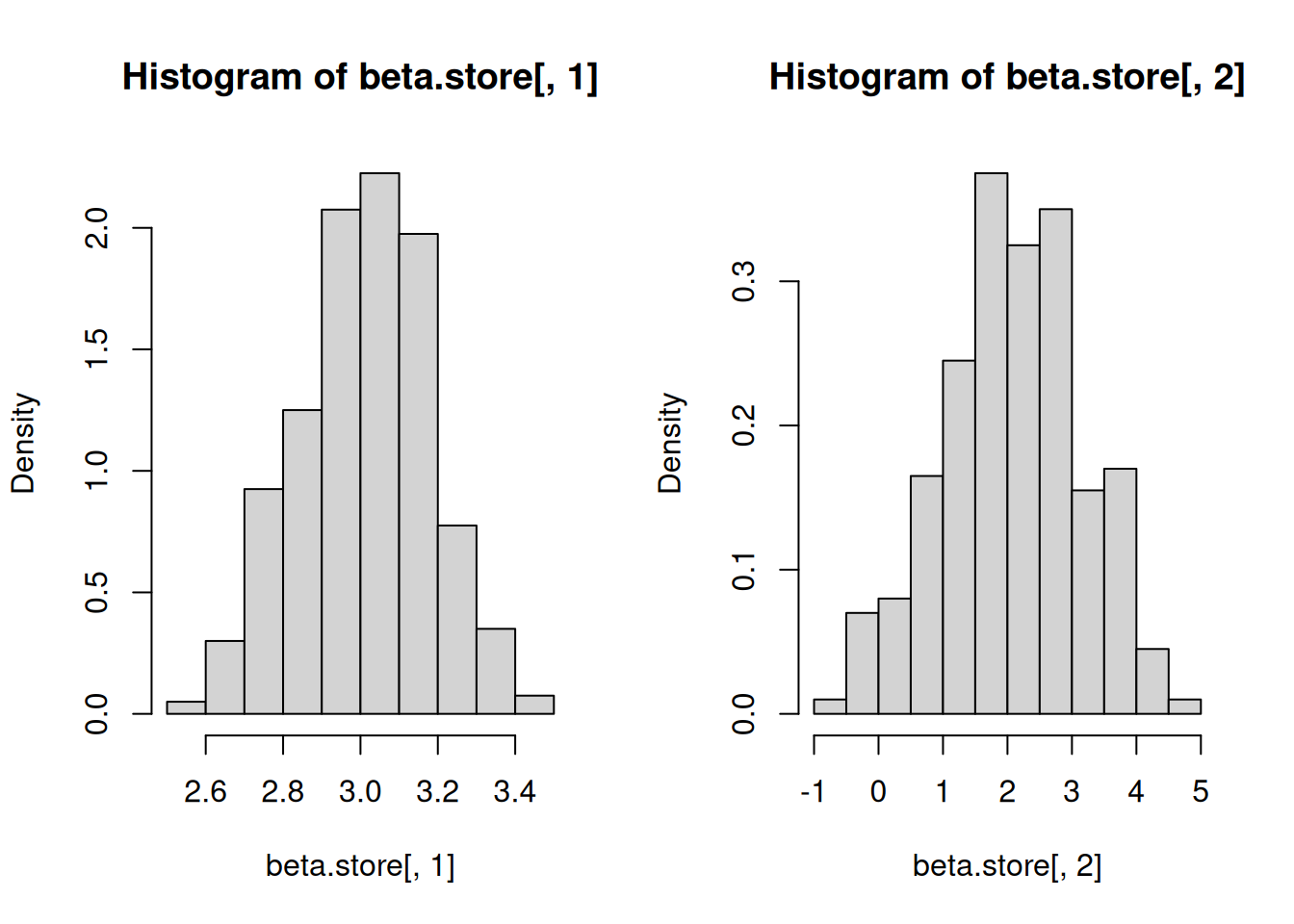
# Number of observationsn <-50# How many times to loopreps <-400# Storage for the results of lm()# 2 entries per replicationbeta.store <-matrix(NA, nrow=reps, ncol=2)# Create a directory to store plot picturesdir.create(paste(getwd(), "/pics/", sep=""))# Loopfor (i in1:reps){ X1.t <-rbinom(n, 1, 0.3) # Generate X1 Y.t <-rnorm(n, 3+2*X1.t, 4*X1.t+1*(1-X1.t)) # Generate Y temp <-lm(Y.t ~ X1.t) beta.store[i,] <-coef(temp) # Create pictures and save on computer filename <-paste(getwd(), "/pics/", i, ".png", sep="")png(filename)plot(X1.t, Y.t)abline(temp)graphics.off()}
# Calculate the column meansapply(beta.store, 2, mean)
[1] 3.011601 2.070685
# Calculate the column SDsapply(beta.store, 2, sd)
[1] 0.170864 1.074949
# Plot histograms side by sidepar(mfrow=c(1,2))hist(beta.store[,1], freq=FALSE)hist(beta.store[,2], freq=FALSE)
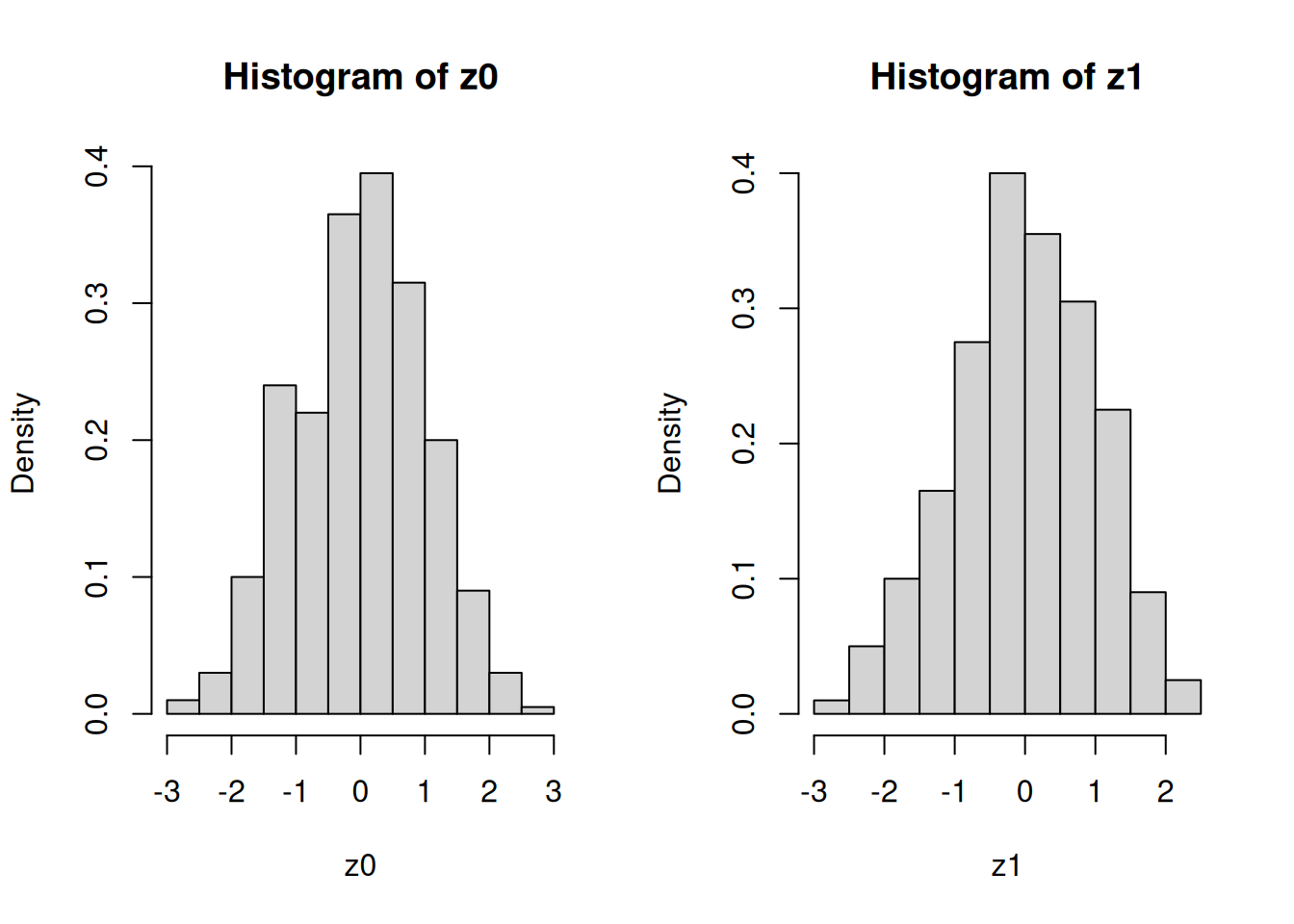
# Standardize each column of beta.storez0 <- (beta.store[,1]-mean(beta.store[,1]))/sd(beta.store[,1])z1 <- (beta.store[,2]-mean(beta.store[,2]))/sd(beta.store[,2])# Plot histograms side by sidepar(mfrow=c(1,2))hist(z0, freq=FALSE)hist(z1, freq=FALSE)
# Get a sense of the distribution of the columns of beta.storec(sum(abs(z0) <1), sum(abs(z0) <2), sum(abs(z0) <3))
There are quite a few new R functions in the code you have just seen. In addition to what you have seen before, I categorize them according to their functionality:
Interacting with files on computer: getwd(), dir.create()
Perhaps the key lines are lines 13 and 14. They indicate how \(X_{1t}\) and \(Y_t\) are to be generated artificially, and the way they were generated mimics the special setup we have – a continuous \(Y\) and a binary \(X_1\).
At the moment, a broad understanding of what is happening would suffice.7 Try evaluating the code on your own computer and then work on the following questions:
Can you describe what you think is being done for lines 15-16?
Calculate the means and standard deviations for each column of beta.store. Focusing on the means of each column of beta.store, can you hazard a guess and give a sense of how the means relate to line 14 of the given code?
You may have encountered the so-called empirical rule. What this rule says is that for bell-shaped distributions, roughly 68% of the observations are within one SD of the mean. In addition, roughly 95% of the observations are within two SDs of the mean. Finally, almost all (about 99%) of the observations are within three SDs. Confirm whether the empirical rule is a good way to describe the simulated data in beta.store.
Open your working directory8 and look inside the pics folder. You will literally see a LOT of scatterplots. Observe how many there are. Describe the scatterplots and lines you see (think of it as a crude animation).
Repeat the simulation but this time alter the number of observations to 200. Redo Items #2 and #5 after this change. Comment on how the column means and column standard deviations have changed.
Compare your findings with some of your classmates. What do you notice?
What should you take home from the Monte Carlo simulation experiments? You saw how lm(), which is really calculating regression coefficients, is behaving in different artificial datasets. Recall that lm() involves functions of averages. From your introductory statistics course, you may have learned about that some operations we apply to the data may have some long-run properties, even though there is some variability ever present in data. In particular, the (sample) average is such an important empirical quantity which has some long-run regularity.
1.2.2 Behavior of the sample average when \(n\to\infty\)
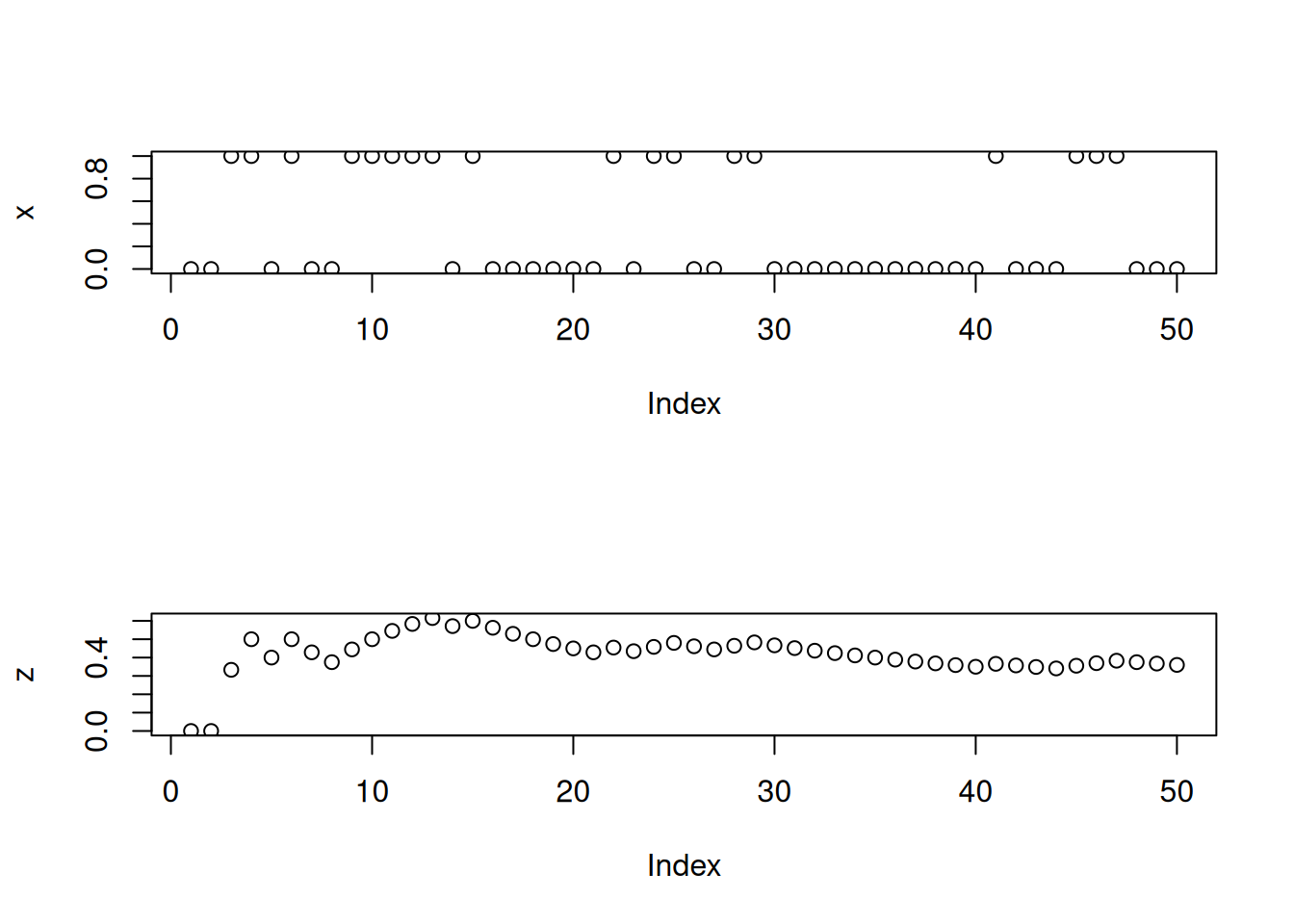
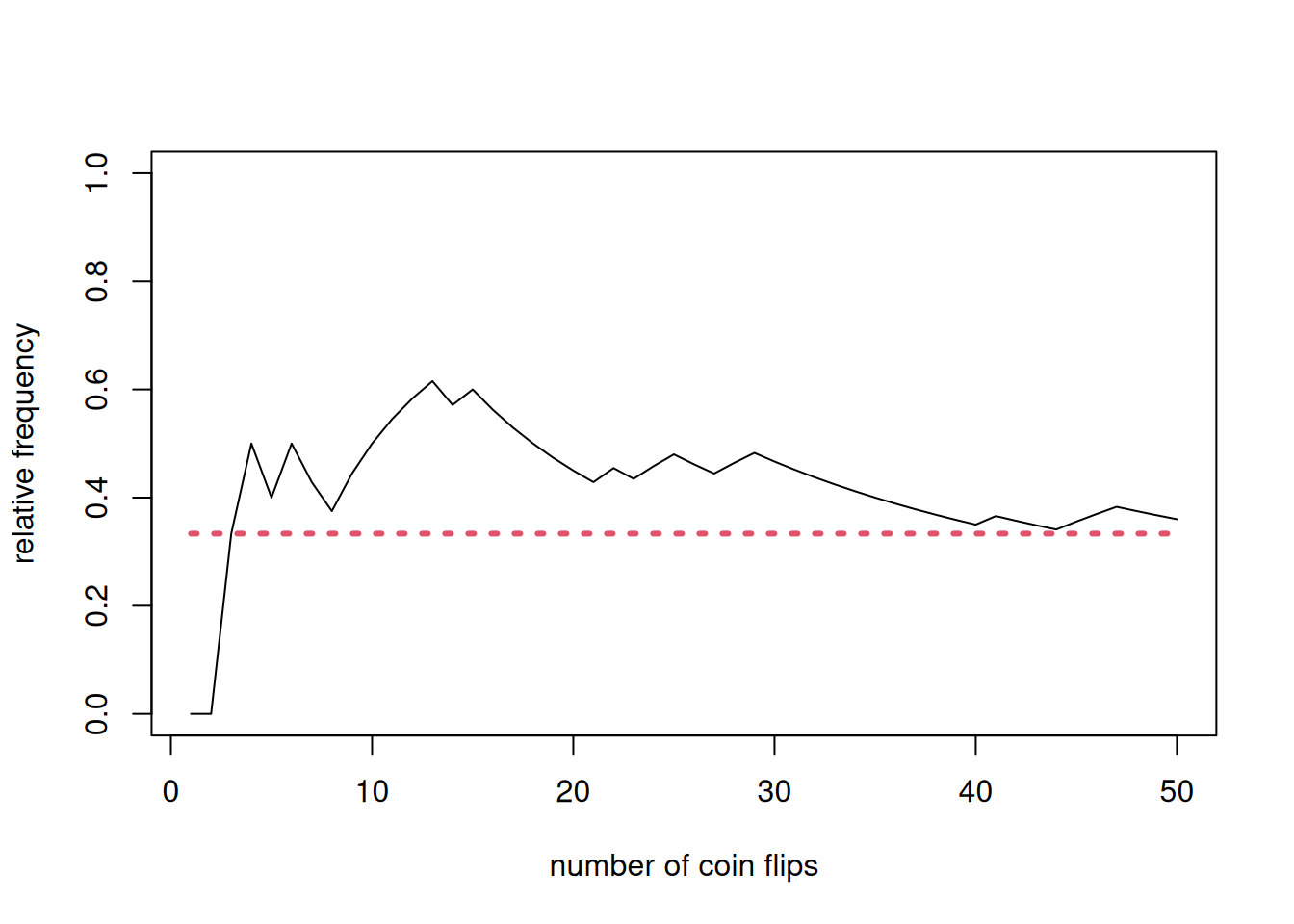
We now consider even simpler: looking at the behavior of the sample average. Let us consider the act of tossing a coin many times and looking at the proportion of heads. Let \(X_t\) be equal to 1 if the \(t\)th coin toss produces heads. Let \(n\) be the number of tosses. Focus on the quantity \[p\left(n\right)=\frac{1}{n} \sum_{t=1}^n X_t\] This is the relative frequency or proportion of heads as a function of the number of tosses.
n <-50p <-1/3x <-rbinom(n, 1, p)z <-cumsum(x)/(1:n)par(mfrow=c(2,1))plot(x)plot(z)
We could design a better picture to highlight some interesting features of \(p(n)\):
# Nicer pictureplot(1:n, z, type ="l", xlab ="number of coin flips", ylab ="relative frequency", ylim =c(0,1))lines(1:n, rep(p, n), lty =3, col =2, lwd =3)
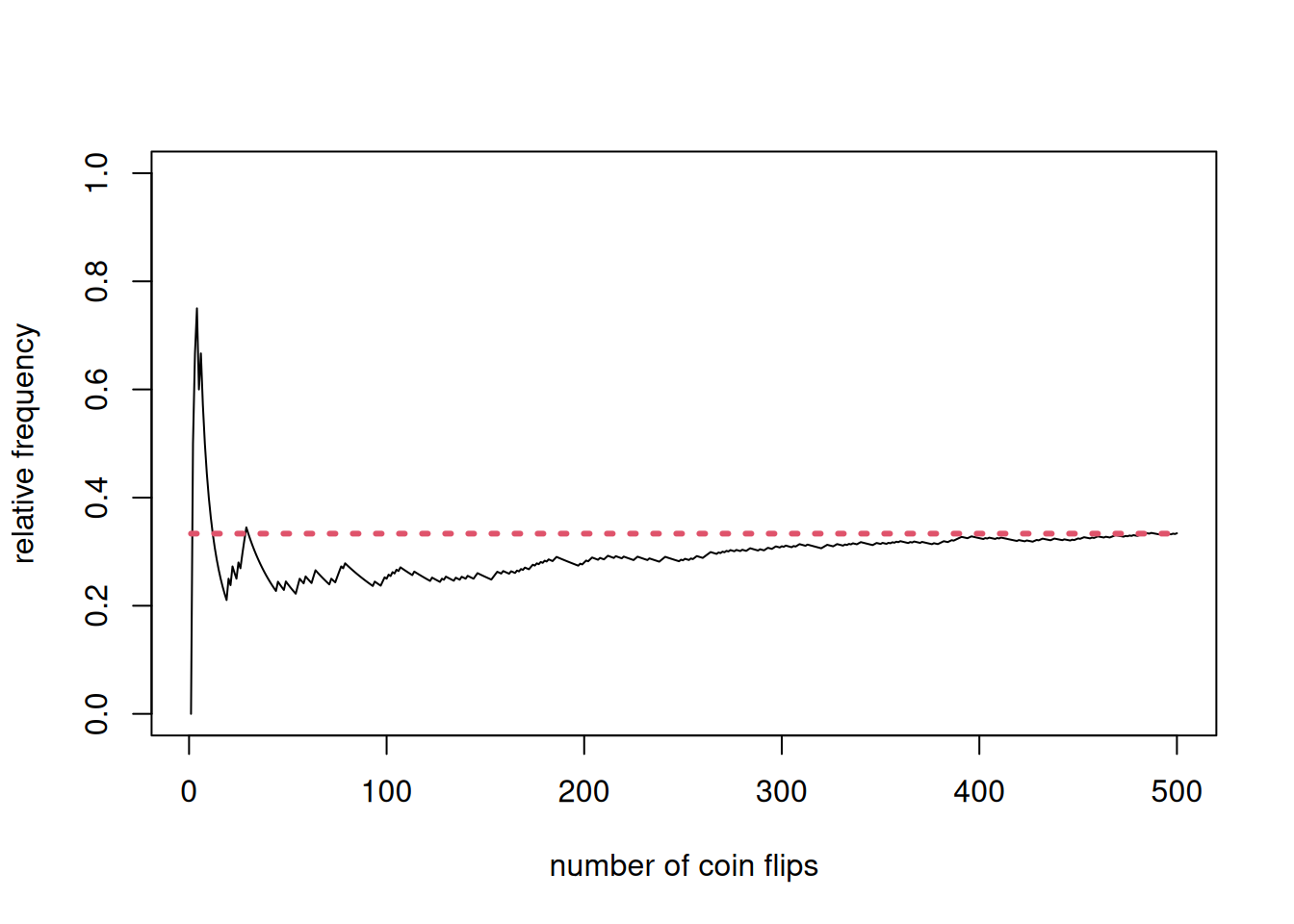
Let us now increase \(n\) to 500.
n <-500p <-1/3; x <-rbinom(n, 1, p); z <-cumsum(x)/(1:n)plot(1:n, z, type ="l", xlab ="number of coin flips", ylab ="relative frequency", ylim =c(0,1))lines(1:n, rep(p, n), lty =3, col =2, lwd =3)
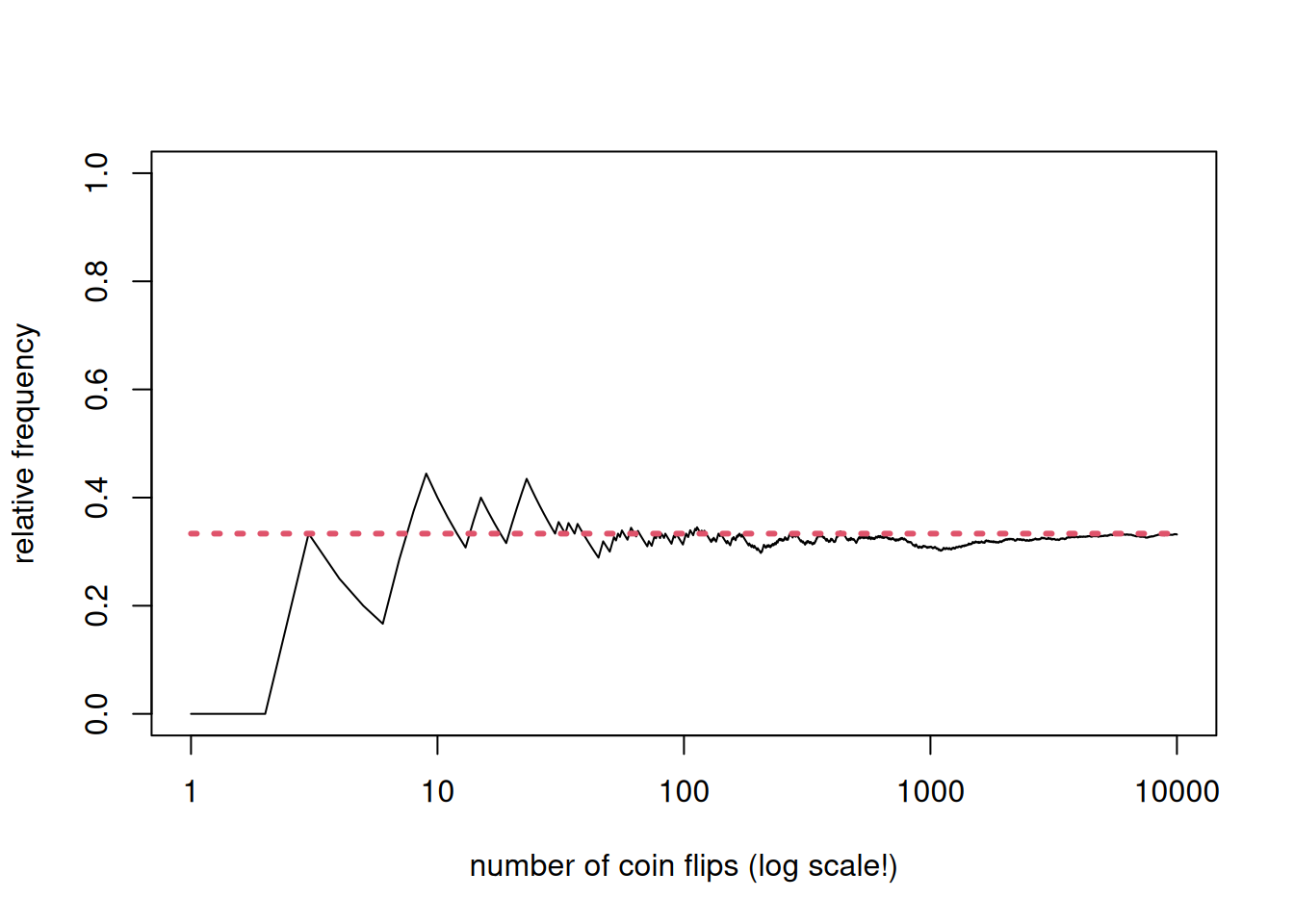
We can further increase \(n\) to 10000.
n <-10000; p <-1/3; x <-rbinom(n, 1, p); z <-cumsum(x)/(1:n)plot(1:n, z, type ="l", xlab ="number of coin flips (log scale!)", ylab ="relative frequency", ylim =c(0,1), log="x")lines(1:n, rep(p, n), lty =3, col =2, lwd =3)
In our coin (whether fair or now) tossing experiments, we are uncertain of the outcomes that will materialize for any specific coin toss. Focusing on the sample average \(p(n)\), there seems to be some form of order emerging in the long run.
Observe that the situation can be cast as a probability model, where we use the language of random variables. \(X_t\) is actually a Bernoulli random variable with probability mass function \(\mathbb{P}\left(X_t=x\right)=p^x (1-p)^x\) where \(x=0, 1\). Another way to express this probability mass function is as \(\mathbb{P}\left(X_t=1\right)=p\) and \(\mathbb{P}\left(X_t=0\right)=1-p\). The expected value of \(X_t\), denoted by \(\mathbb{E}\left(X_t\right)=p\).
From our visualizations, there is some sense in which \(p(n)\) converges to \(p\). We will return to convergence concepts later. It suffices that you are aware that \(p(n)\) is also a random variable having some “order” where it behaves like a constant \(p\) in the long run. This is probably the simplest illustration of the law of large numbers.
1.2.3 Behavior of the sample average in repeated sampling
Another way to approach the “order” we have seen earlier is to look at the sample average in a repeated sampling context. Some new R functions like replicate(), colMeans(), and table() are introduced.
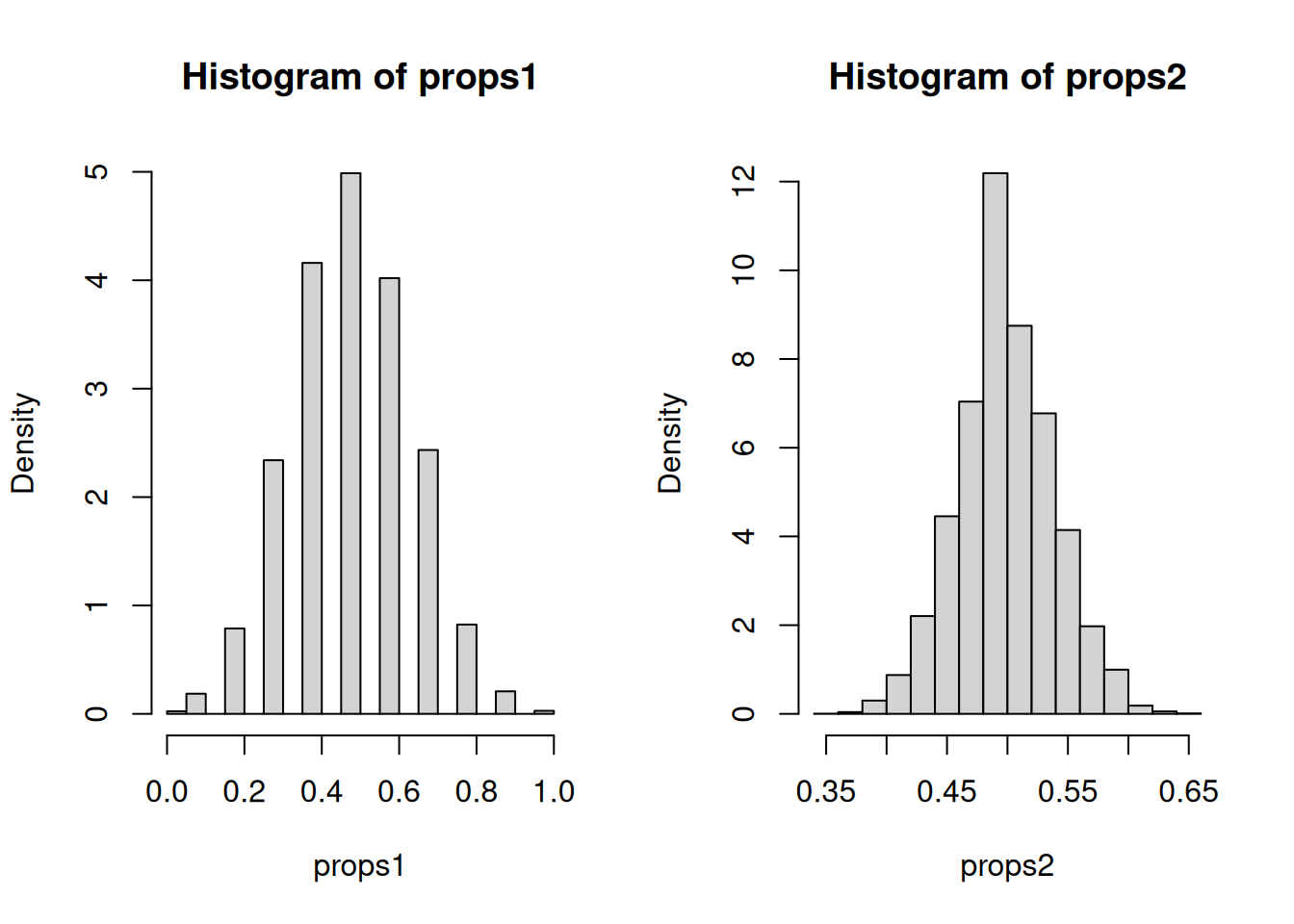
# Set the number of repetitionsnsim <-10^4# Repeat for `nsim` times "tossing of a fair coin 10 times"set1 <-replicate(nsim, rbinom(10, 1, 0.5))# Repeat for `nsim` times "tossing of a fair coin 160 times"set2 <-replicate(nsim, rbinom(160, 1, 0.5))# Calculate the relative frequency for every repetitionprops1 <-colMeans(set1)props2 <-colMeans(set2)# Display the empirical distribution of relative frequenciestable(props1)
# Calculate the mean and SD of the distributionc(mean(props2), sd(props2))
[1] 0.49927563 0.03960601
# Display the histogram of relative frequencies# Pay attention to the axes of the plotspar(mfrow=c(1,2))hist(props1, freq=FALSE)hist(props2, freq=FALSE)
When we apply the sample average \(p(n)\) repeatedly and collect the sample averages across repetitions, the histogram of sample averages has a resulting center, spread, and shape. Notice what is happening as the number of tosses increases. When we use the sample, there is another form of order emerging in the long run, especially with respect to the histogram of sample averages.
Observe that \(X_1,\ldots,X_n\) are IID random variables with \[\mathbb{E}\left(p(n)\right)=p,\ \ \mathsf{Var}\left(p(n)\right)=\frac{p(1-p)}{n}\] Based on these calculations, try to make sense of the center and spread of the histogram of sample means. Later, we will make sense of the shape.
1.3 As a way to make predictions
What you have seen so far is that linear regressions provide specific summaries of the data. You have seen that the coefficients produced by lm() can be motivated as an outcome of a least squares problem. What is not very clear is the origins of the form of the least squares problem. How did we know that this is the least squares problem to set up?
You have also seen a Monte Carlo simulation to give you a sense of the behavior of the coefficients produced by lm(). The coefficients produced depend on the dataset on hand and they can be thought of as empirical quantities which are subject to variation. You have actually seen crude animations to this effect.
To truly understand what these empirical quantities are actually all about, we cannot avoid abstraction. What I mean by abstraction is that we are engaging in a thought experiment where we think of empirical quantities as having some “order” which could be studied mathematically. You have seen this “order” arising from our coin tossing experiments.
We now are going to connect all of these strands and see how they form the basis of understanding linear regressions as a way to make predictions.
1.3.1 Best (optimal) linear prediction
One of the four words in the sentence “I SEE THE MOUSE” will be selected at random. This means that each of these words are equally likely to be chosen. The task is to predict the number of letters in the selected word.
To even start with fulfilling this task, we need to specify some criterion to judge whether the prediction is “good” or not. We can start by looking at the error, which would be the number of letters minus the predicted number of letters. But there is not much we can do by just looking at the error because we do not know for sure which word will be chosen. As a result, your prediction should have to allow for contingencies.
At this point, you need the language of random variables, which were introduced in your first course in statistics. There is some random variable \(Y\) whose value you want to predict. You have to specify a prediction rule. An example is an unknown real number \(\beta_0\). You make an error \(Y-\beta_0\), but this error is also a random variable having a distribution.
Next, you need some criterion to assess whether your prediction is “good”. This criterion is called a loss function and there are many choices, which are not limited to: \[L\left(z\right)=z^{2},L\left(z\right)=\left|z\right|,L\left(z\right)=\begin{cases}
\left(1-\alpha\right)\left|z\right| & \mathsf{if}\ z\leq0\\
\alpha\left|z\right| & \mathsf{if}\ z\geq0
\end{cases}\] These are referred to as squared loss, absolute loss, and asymmetric loss, respectively. But losses will have a distribution too. We can choose to target expected losses. This may seem arbitrary but many prediction and forecasting contexts use expected losses.
Consider squared loss\(L\left(z\right)=z^{2}\) and form an expected squared loss \(\mathbb{E}\left[\left(Y-\beta_0\right)^{2}\right]\). This expected loss is sometimes called mean squared error (MSE). You can show that \(\mathbb{E}\left(Y\right)\) is the unique solution to the following optimization problem: \[\min_{\beta_0}\mathbb{E}\left[\left(Y-\beta_0\right)^{2}\right] \tag{1.4}\]
We also have a neat connection with the definition of the variance. \(\mathsf{Var}\left(Y\right)\) becomes the smallest expected loss from using \(\mathbb{E}\left(Y\right)\) as your prediction for \(Y\).
Do you see any similarities with what you have seen before? How about the connections and parallels to simple linear regression as a summary? How about the differences?
1.3.2 Incorporating additional information in best linear prediction
Return to our toy example of I SEE THE MOUSE. We still want to predict the number of letters \(Y\) in the selected word. But this time you are given additional information: the number of E’s in the word. Denote the number of E’s as \(X_1\).
How do we incorporate this additional information for prediction? We have to change the specification of our prediction rule. Earlier, we considered and unknown real number \(\beta_0\) as a prediction rule. Clearly, knowing the value of \(X_1\) for the selected word could help. Therefore, we can specify \(\beta_0+\beta_1 X_1\) as a prediction rule.
We repeat the process of calculating the MSE but for a new specification of the prediction rule. Under an MSE criterion, the minimization problem is now \[\min_{\beta_{0},\beta_{1}}\mathbb{E}\left[\left(Y-\beta_{0}-\beta_{1}X_1\right)^{2}\right], \tag{1.5}\] with optimal coefficients \(\beta_{0}^{*}\) and \(\beta_{1}^{*}\) satisfying the first-order conditions: \[\mathbb{E}\left(Y-\beta_{0}^{*}-\beta_{1}^{*}X_1\right) = 0, \ \
\mathbb{E}\left[X_1\left(Y-\beta_{0}^{*}-\beta_{1}^{*}X_1\right)\right] = 0\]
As a result, we have \[\beta_{0}^{*} = \mathbb{E}\left(Y\right)-\beta_{1}^{*}\mathbb{E}\left(X_{1}\right),\qquad\beta_{1}^{*}=\dfrac{\mathbb{E}\left(X_1Y\right)-\mathbb{E}\left(Y\right)\mathbb{E}\left(X_1\right)}{\mathbb{E}\left(X_1^2\right)-\mathbb{E}\left(X_1\right)^2}.\]
In the end, we can rewrite as \[\beta_{0}^{*} = \mathbb{E}\left(Y\right)-\beta_{1}^{*}\mathbb{E}\left(X_{1}\right),\qquad\beta_{1}^{*}=\dfrac{\mathsf{Cov}\left(X_{1},Y\right)}{\mathsf{Var}\left(X_{1}\right)}. \tag{1.6}\]
Take note of how we computed linear regression in lm(). Do you find some similarities and parallels? What are the differences?
1.3.3 I SEE THE MOUSE
Recall that the task is to predict the number of letters in the selected word. Each word is equally likely to be chosen. Let \(Y\) be the number of letters in the selected word. The best predictor under an MSE criterion for \(Y\) is \(\mathbb{E}\left(Y\right)\). Here, we have \(\mathbb{E}\left(Y\right)=3\).
If we have information on the number of E’s in the word, what will be your prediction? Let \(X_1\) denote the number of E’s in the word. We have found a formula for the best linear predictor which is \(\beta_0^* +\beta_1^*X_1\), where \(\beta_0^*\) and \(\beta_1^*\) have forms we have derived earlier. You can show that the best linear predictor is \(2+X_1\). Notice that this best linear predictor uses information about the number of E’s in the word to make predictions. Contrast this to the case where we did not know the number of E’s in the word.
Let us now conduct a Monte Carlo simulation to see what we learn from lm(). We know that
The best linear predictor of \(Y\) for I SEE THE MOUSE is \(3\).
The best linear predictor of \(Y\) given \(X_1\) for I SEE THE MOUSE is \(2+X_1\).
We mimic the sampling of random pairs from the joint distribution of \((X_1,Y)\), according to the context of I SEE THE MOUSE. The pairs of possible outcomes can be found in the code as the object source. The sampled pairs \(\left(Y_1, X_{11}\right), \left(Y_2, X_{12}\right), \ldots, \left(Y_n, X_{1n}\right)\) are found in the code as the object data. After that, we record the coefficients obtained when we apply lm(Y ~1) and lm(Y ~ 1 + X1).9 What do you notice?
# Two storages for coefficients produced by lm()coefs0 <-matrix(NA, nrow=10^4, ncol=1)coefs <-matrix(NA, nrow=10^4, ncol=2)# The possible outcomes of (Y, X1)source <-matrix(c(1,3,3,5,0,2,1,1), ncol=2)source
[,1] [,2]
[1,] 1 0
[2,] 3 2
[3,] 3 1
[4,] 5 1
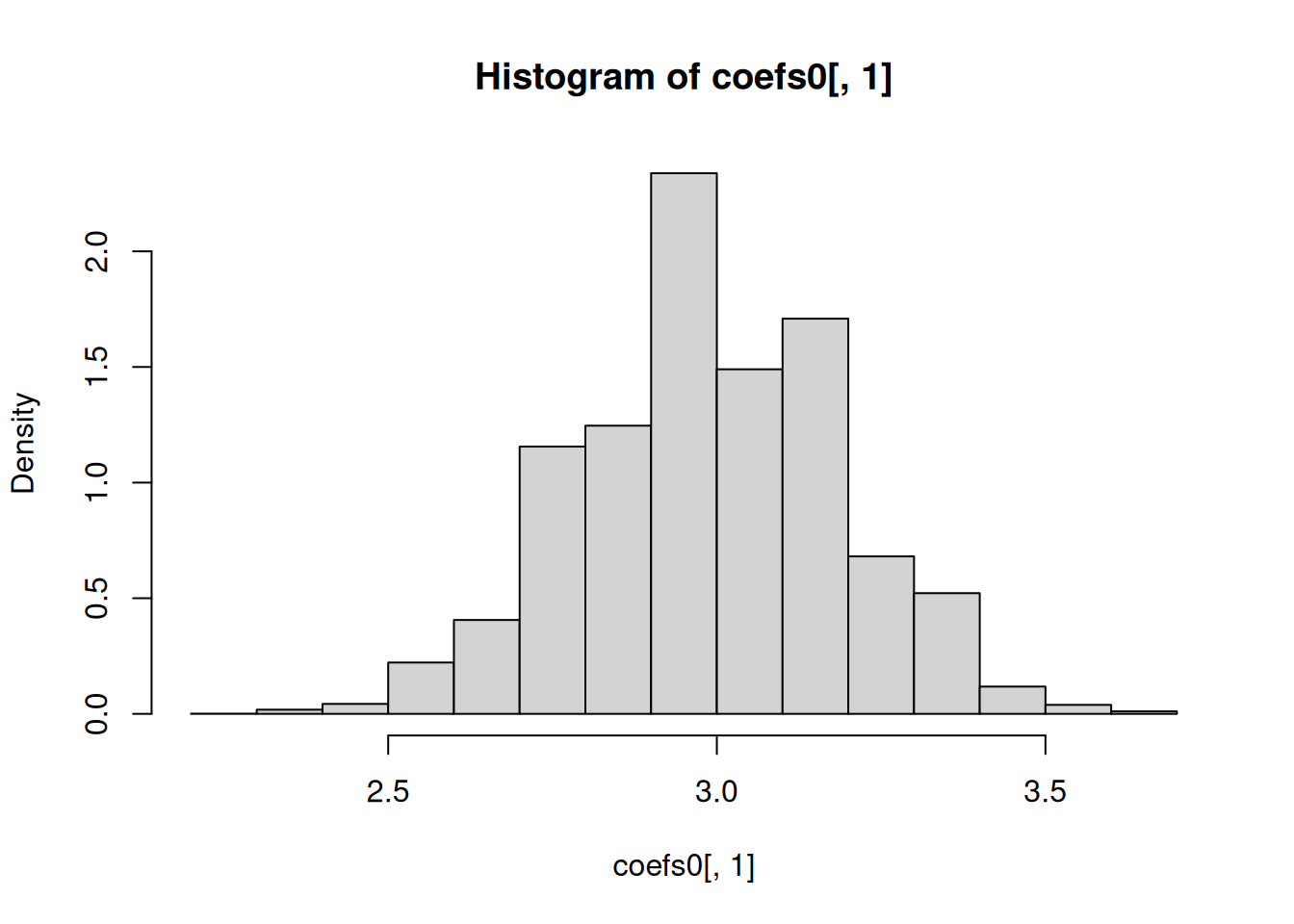
# Number of observationsn <-50# Number of repetitionsreps <-10^4for(i in1:reps){ data <-data.frame(source[sample(nrow(source),size=n,replace=TRUE),])names(data) <-c("Y", "X1") temp0 <-lm(Y ~1, data = data) coefs0[i, ] <-coef(temp0) temp <-lm(Y ~1+ X1, data = data) coefs[i, ] <-coef(temp)}# Histogram of regression coefficientspar(mfrow=c(1,1))hist(coefs0[,1], freq =FALSE)
# Center and spreadc(mean(coefs0[,1]), sd(coefs0[,1]))
[1] 2.999736 0.200189
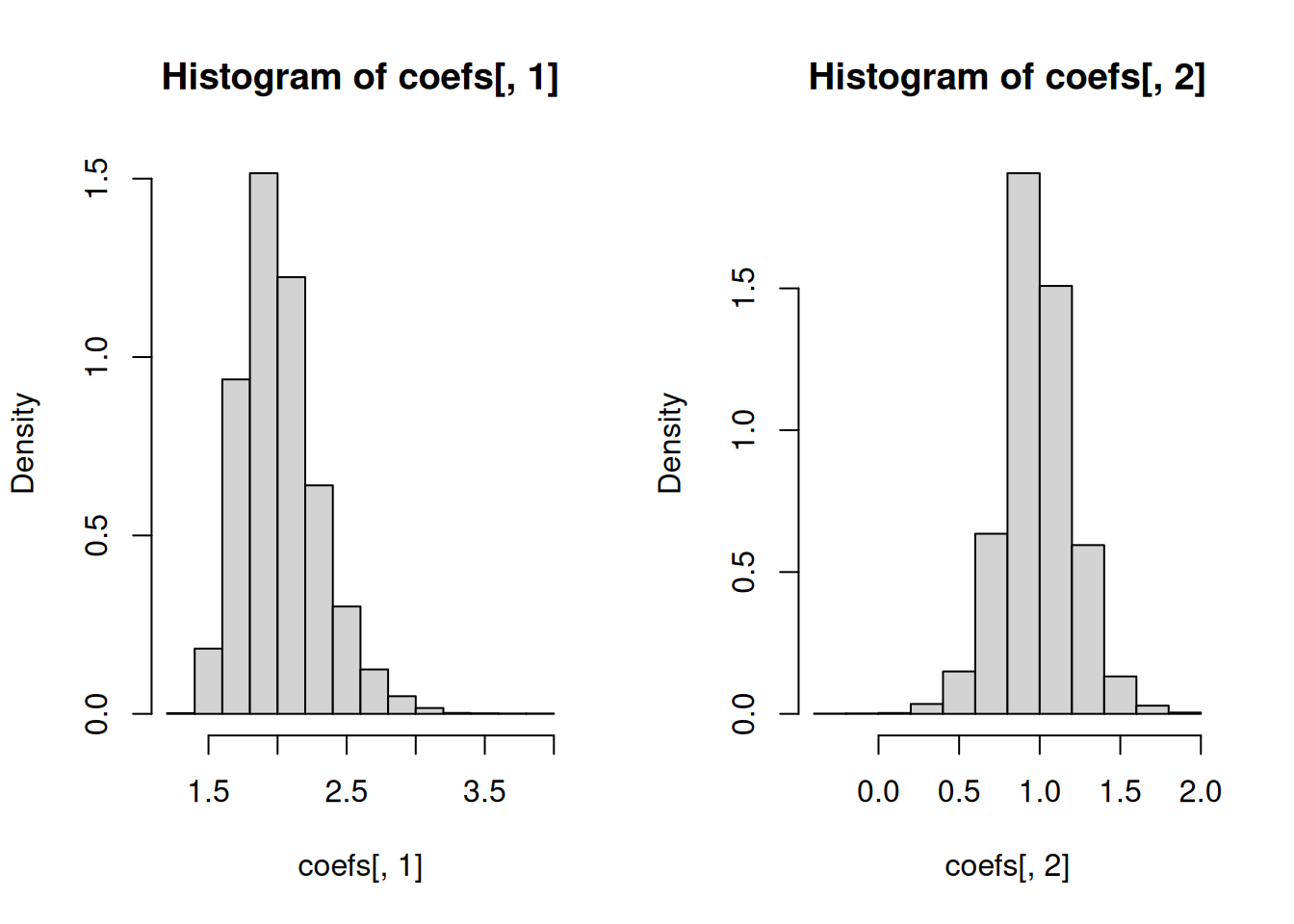
# Histogram of regression coefficientspar(mfrow=c(1,2))hist(coefs[,1], freq =FALSE)hist(coefs[,2], freq =FALSE)
# Center and spreadc(mean(coefs[,1]), sd(coefs[,1]))
[1] 2.0227455 0.2858863
c(mean(coefs[,2]), sd(coefs[,2]))
[1] 0.9962469 0.2186377
1.3.4 Interpreting linear regressions
What you see from the theory is that lm() produces regression coefficients which, in the long run, behave like the optimal coefficients of the best linear predictor. Therefore, regression coefficients have meaning in the context of prediction. You can see a confirmation of these findings from the Monte Carlo simulation of I SEE THE MOUSE.
Now, let us consider a slightly more general case where \(Y\) is continuous and \(X_1\) is binary (coded as 0/1). What would be the meaning of the regression coefficients produced by lm() in the long run? The best linear prediction of \(Y\) given \(X_1\) is \(\beta_0^*+\beta_1^* X_1\). Therefore,
The best linear prediction of \(Y\) given \(X_1=0\) is \(\beta_0^*\).
The best linear prediction of \(Y\) given \(X_1=1\) is \(\beta_0^*+\beta_1^*\).
When we compare the best linear predictions of \(Y\) for cases where \(X_1=1\) against cases where \(X_1=0\), the predicted difference between those cases is \(\beta_1^*\).
In fact, we can extend to the most general case where any of \(Y\) and \(X_1\) could be discrete (not just binary) or continuous. In particular,
The best linear prediction of \(Y\) given \(X_1=0\) is \(\beta_0^*\).
The best linear prediction of \(Y\) given \(X_1=x\) is \(\beta_0^*+\beta_1^*x\).
The best linear prediction of \(Y\) given \(X_1=x+1\) is \(\beta_0^*+\beta_1^*(x+1)\).
When we compare the best linear predictions of \(Y\) for cases where \(X_1=x+1\) against cases where \(X_1=x\), the predicted difference between those cases is \(\beta_1^*\).
The extension to the general case is valid because the empirical minimization problems based on the sample (Equation 1.1 and Equation 1.2) and their corresponding prediction counterparts based on the population (Equation 1.4 and Equation 1.5) do not depend on whether \(Y\) and/or \(X_1\) are discrete or continuous.
In practice, the interpretations you have seen have to be based on the calculations from the data you actually have. This means that we will replace \(\beta_0^*, \beta_1^*\) with \(\widehat{\beta}_0, \widehat{\beta}_1\), respectively. This replacement is justifiable because we have some knowledge of the expected behavior of the procedure which generated \(\widehat{\beta}_0, \widehat{\beta}_1\).
Let us now apply this finding in the context of our course evaluation example. Consider a linear regression of course_eval on female and another linear regression of course_eval on beauty. We have encountered the former before in Section 1.1.1. I will call the latter reg3. Both are still simple linear regressions.
How do we interpret the coefficients in reg2 and reg3? The aim is to provide a truthful and understandable way of communicating the results. One way to achieve this aim for reg2 is as follows:
The best linear prediction of the course evaluation for courses taught by male instructors is equal to 4.1 points.
The best linear prediction of course evaluation for courses taught by female instructors is 0.2 points lower than the best linear prediction of course evaluation for courses taught by male instructors.
For reg3, it would be helpful to get a sense of the scale and units of measurement for beauty. Hamermesh and Parker (2005) write:
Each of the instructors’ pictures was rated by each of six undergraduate students: three women and three men, with one of each gender being a lower division, two upper-division students (to accord with the distribution of classes across the two levels). The raters were told to use a 10 (highest) to 1 rating scale, to concentrate on the physiognomy of the instructor in the picture, to make their ratings independent of age, and to keep 5 in mind as an average. In the analyses we unit normalized each rating. To reduce measurement error the six normalized ratings were summed to create a composite standardized beauty rating for each instructor.
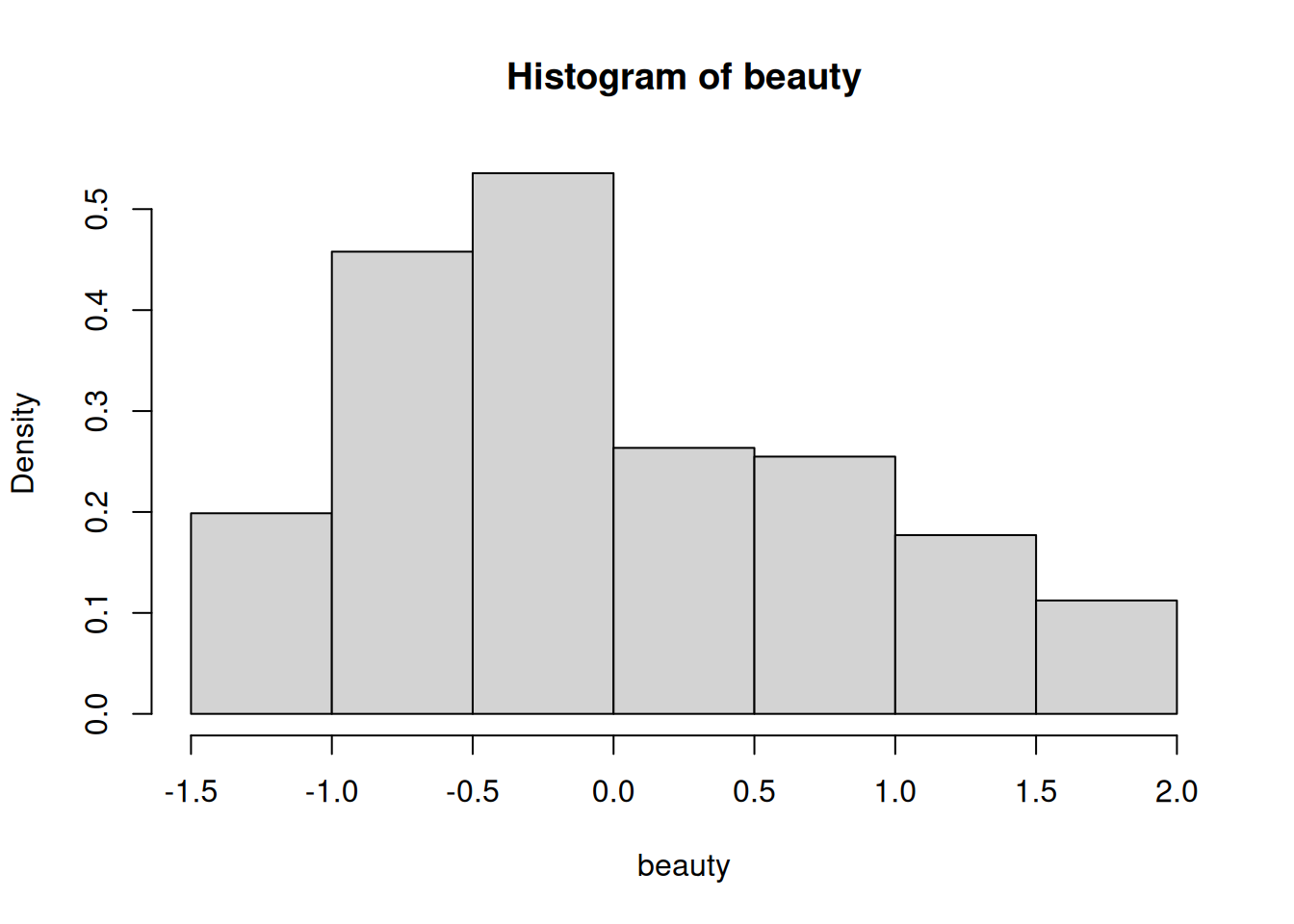
The variable beauty has no units because it is standardized. Below you will find summary statistics related to the distribution of beauty in the sample.
with(ratings, summary(beauty))
Min. 1st Qu. Median Mean 3rd Qu. Max.
-1.45049 -0.65627 -0.06801 0.00000 0.54560 1.97002
with(ratings, sd(beauty))
[1] 0.7886477
with(ratings, hist(beauty, freq =FALSE))
A first attempt at truthful and understandable interpretation for reg3 could be:
The best linear prediction of the course evaluation for courses taught by instructors with a standardized beauty rating of zero is equal to 4 points.
The best linear prediction of course evaluation for courses taught by instructors with a standardized beauty rating of 1.5 is 0.1 points higher than the best linear prediction of course evaluation for courses taught by instructors with a standardized beauty rating of 0.5.
When interpretations were communicated, observe that the interpretations involved making choices. These include:
being specific about the form upon which a prediction is based: I used a linear prediction rule, because I used lm() to obtain the results.
not reporting all decimal places: I rounded off to the nearest tenth.
choosing the levels of standardized beauty ratings and the cases to be compared: I chose the third quartile of the standardized beauty ratings. But it should not matter which level I chose given the way I used lm().10
specifying the units of measurement: Although beauty does not have units, course_eval is in points on a 0 to 5 scale.
The interpretations do not read as “sexy” at all, but they were communicated truthfully and in a somewhat understandable manner. There is still some room for improvement, for example:
We predict that the course evaluation of instructors who were rated as average in terms of their beauty would be equal to 4 points.
Courses having instructors whose beauty ratings are one standard deviation above average are predicted to have course evaluations which are 0.2 points higher than courses having instructors whose beauty ratings are one standard deviation below average.
To obtain the predicted difference of 0.2 points, we need the regression coefficients from reg3 and the standard deviation of the standardized beauty ratings. So, we have
The best linear prediction of course evaluation for courses taught by instructors with a standardized beauty rating of one standard deviation above the average is \[\begin{eqnarray} &\widehat{\beta}_0+\widehat{\beta}_1 \times \left(\mathrm{one\ SD\ of \ standardized\ beauty\ ratings\ above \ average}\right) \\ & \approx 3.998+0.133(0.7886) \approx 4.103\end{eqnarray}\] points.
The best linear prediction of course evaluation for courses taught by instructors with a standardized beauty rating of one standard deviation below the average is \[\begin{eqnarray}& \widehat{\beta}_0+\widehat{\beta}_1 \times \left(\mathrm{one\ SD\ of \ standardized\ beauty\ ratings\ below \ average}\right) \\ & \approx 3.998+0.133(-0.7886) \approx 3.893\end{eqnarray}\] points.
The predicted difference is \(4.103-3.893=0.21\) points, which is roughly 0.2 points in the interpretation.
Compare the previous interpretation to what was provided in Hamermesh and Parker (2005):
Moving from one standard deviation below the mean to one standard deviation above leads to an increase in the average class rating of 0.46, close to a one-standard deviation increase in the average class rating.
We don’t exactly communicate similar findings for three major reasons:
We are only working with a subset of the original data.
They use multiple linear regression rather than just simple linear regression.
The interpretation Hamermesh and Parker (2005) seems to be more than just predictive. You may want to refer to Section 4 of their paper to get a sense of what they had in mind.
As you have more complex linear regressions, the interpretations would roughly be similar with some adjustments. These adjustments will be explored in the next chapter when we start handling the possibility that your variables were transformed and you have more than just one \(X\).
1.4 As a way to make causal statements
1.4.1 Linear regression versus linear regression model
Let us revisit best linear prediction of some random variable \(Y\). Define\(U\) to be the error produced by a best linear prediction of \(Y\), i.e. \[U=Y-\beta_0^*.\] From the optimality of \(\beta_0^*\), we can conclude that \[\mathbb{E}\left(U\right)=0.\] As a result, we can always write \[Y=\beta_0^*+U\] where \(U\) satisfies \(\mathbb{E}\left(U\right)=0\) if we are focused on prediction.
What I just described is also related to a basic form of a “signal plus noise” model used in statistics and econometrics. In fact, many textbooks directly assume (or implicitly assume) that \[Y=\beta_0+\mathrm{error}\] with \(\beta_0\) unknown and \(\mathbb{E}\left(\mathrm{error}\right)=0\). The task is then to recover \(\beta_0\).
How is this “signal plus noise” model related to linear regression? The term \(\mathrm{error}\) in the “signal plus noise” model was assumed to have a property that \(\mathbb{E}\left(\mathrm{error}\right)=0\). Effectively, the term \(\mathrm{error}\) is also an error produced by best linear prediction of \(Y\), because of its zero population mean property. Therefore, the unknown \(\beta_0\) would have to be equal to \(\beta_0^*\). We also know that linear regression, specifically using lm(Y ~ 1), allows us to recover \(\beta_0^*\)in the long run.
Another version of the simple “signal plus noise” model is as follows. Assume that \[Y=\beta_0+\beta_1X_1+\mathrm{error}\] with \(\beta_0,\beta_1\) being unknown, \(\mathbb{E}\left(\mathrm{error}\right)=0\), and \(\mathsf{Cov}\left(X_1,\mathrm{error}\right)=0\). Take note that although I am using the same notation \(\mathrm{error}\) as earlier, they represent different error terms. This version is sometimes called a simple linear regression model. The task is then to recover \(\beta_0,\beta_1\).
How is this simple linear regression model related to linear regression? The term \(\mathrm{error}\) was assumed to have properties that \(\mathbb{E}\left(\mathrm{error}\right)=0\) and \(\mathsf{Cov}\left(X_1,\mathrm{error}\right)=0\). Effectively, the term \(\mathrm{error}\) is also an error produced by best linear prediction of \(Y\) given \(X_1\). Therefore, the unknown \(\beta_0,\beta_1\) is actually equal to \(\beta_0^*\) and \(\beta_1^*\), respectively. We also know that linear regression, specifically using lm(Y ~ 1 + X1), allows us to recover \(\beta_0^*\) and \(\beta_1^*\)in the long run.
In my opinion, starting from a “signal plus noise” model or a simple linear regression model may not be the most appropriate. Why?
It mixes up two things: linear regression as a way to calculate coefficients and a linear regression model as the assumed underlying data generating process.
It is not clear why a linear regression model would be assumed. In contrast, by being very specific at the beginning about prediction tasks, we do not even need to have a model of how the data were generated. All we need for the theory to work is the presence of a joint distribution of \((Y,X_1)\) with finite variances.
Therefore, if you find yourself reading a paper or book or any other material where they use linear regression or a linear regression model, you have to figure out what exactly they are doing and what exactly they are assuming.
The most unsatisfying aspect of seeing a linear regression model is the unclear nature of the origins of the assumed form. For example, stating that \(Y=\beta_0+\beta_1 X_1+\mathrm{error}\), where \(\mathrm{error}\) satisfies \(\mathbb{E}\left(\mathrm{error}\right)=0\) and \(\mathsf{Cov}\left(X_1,\mathrm{error}\right)=0\), is an assumption. Although we can use linear regressions to recover \(\beta_0\) and \(\beta_1\) under some conditions, an analysis solely relying on this assumption without a justification or without a clear research question is inadequate. In Chapter 2, we will see a classic example where both justification and a clear research question are present.
1.4.2 Building a simple causal model
At this point, we now want to determine the effect of some variable \(X_1\) on the outcome \(Y\). Establishing causal statements typically rely on counterfactuals. What are counterfactuals? Suppose there was an intervention that changes \(X_1\) and we want to measure how \(Y\) changes as a result of that intervention. We need to know what would have happened had \(X_1\) not change, but this did not happen at all. Therefore, we require an analysis which runs “counter to the facts”. Hence, you see the word “counterfactual”.
In contrast, we have spent most of our time talking about making comparisons and these comparisons are based on differences from best linear predictions. When we made comparisons before, we were making comparisons across different subgroups – apples to oranges! In contrast, the comparisons have to be apples to apples and oranges to oranges in order to establish causality!
In order to make apples to apples or oranges to oranges comparisons, we have to further establish new language. This means we need new notation to reflect the fact that we are comparing the outcomes of the same unit.
Suppose there is a policy variable \(X_1\) and you want to evaluate the effects of this policy. How would you evaluate the effect of the policy in the first place?
You need to tie the policy variable \(X_1\) to outcomes which could be measured. Let us focus on a single outcome \(Y\).
We also need to define the effect we are looking for.
We also have to allow for the possibility that we are unable to measure all other variables denoted by \(U\), aside from the policy variable, which can affect \(Y\). Note that \(U\) is not the error from best linear prediction.
As a result, we have a triple \((Y,X_1,U)\) but we can only observe \((Y,X_1)\) for purposes of evaluating policy. We are going to assume a causal model or a structural equation or a response schedule of the form: \[Y\left(X_1,U\right)=\alpha+\lambda X_1+\gamma U \tag{1.7}\]
Let \(x\) be the level of \(X_1\) for the \(t\)th unit. Define the causal effect of \(X_1\) on \(Y\) for the unit \(t\) as \[Y_t\left(x+1,U_t\right)-Y_t\left(x,U_t\right).\] This difference represents how \(Y\) for the \(t\)th unit changes when the \(t\)th unit’s \(X_1\) changes by 1 unit, holding the \(t\)th unit’s \(U\) constant.
The causal effect in Equation 1.7 for this particular case of a structural equation is given by \[\alpha+\lambda (x+1)+\gamma U_t - \left(\alpha+\lambda x+\gamma U_t\right)=\lambda.\] The million-dollar question is really what happens when I compute a linear regression of \(Y\) on \(X_1\). Do I recover \(\lambda\)?
You already know that when we have IID draws \(\left(Y_1, X_{11}\right), \left(Y_2, X_{12}\right), \ldots, \left(Y_n, X_{1n}\right)\), we have, as \(n\to\infty\), the linear regression procedure which produces \(\widehat{\beta}_1\) behaves like \[\beta_1^* = \frac{\mathsf{Cov}\left(Y,X_1\right)}{\mathsf{Var}\left(X_1\right)}\] The issue is if \(\beta_1^*\) actually equals \(\lambda\)!
If \(\beta_1^*=\lambda\), then you can use linear regression to recover the desired causal effect. If it does not, then you use something else other than linear regression, think a bit harder, or make plausible assumptions which will allow you to still use linear regression to recover \(\lambda\).
You can show that \[\beta_1^* =\frac{\mathsf{Cov}\left(Y,X_1\right)}{\mathsf{Var}\left(X_1\right)}=\lambda+\gamma\frac{\mathsf{Cov}\left(U,X_1\right)}{\mathsf{Var}\left(X_1\right)} \tag{1.8}\] Thus, if \(\mathsf{Cov}\left(U,X_1\right)=0\), then you can recover \(\lambda\).
This means that if we have evidence that \(\mathsf{Cov}\left(U,X_1\right)=0\), we can use a linear regression of \(Y\) on \(X_1\) to recover \(\lambda\) even if we do not observe \(U\).
But the problem is that in practice the unobserved variables \(U\) are such that \(\mathsf{Cov}\left(U,X_1\right)\neq 0\). Observe that:
Even if we assume a simple linear regression model of the form \[Y=\beta_0+\beta_1 X_1+\mathrm{error}\] So, even if \(\mathsf{Cov}\left(X_1,\mathrm{error}\right)=0\), we still could not recover \(\lambda\) even after calculating a linear regression of \(Y\) on \(X_1\).
Even if we can always write \(Y=\beta_0^*+\beta_1^* X_1+U\) from a predictive perspective, \(U\) in Equation 1.7 is not the error from best linear prediction.
Statistical error terms like \(\mathrm{error}\) or prediction errors like \(U\) are fundamentally different from unobserved errors \(U\) in the causal model! Notice that even if we use the same notation \(U\), the contexts upon which \(U\) arises are just different. This was recently reiterated in the main point of Crudu et al. (2022).
The new language and the framework we just discussed provides us what to look for in real applications. The idea is to ensure \(\mathsf{Cov}\left(U,X_1\right)=0\). Randomized controlled trials (RCTs) may provide a setting to achieve this.
In RCTs, investigators assign subjects at random to a treatment group \(X_1=1\) or to a control group \(X_1=0\). Data collection can be expensive and ethical issues do arise in RCTs. But if designed properly, RCTs will ensure the independence of \(U\) and \(X_1\), which will then imply \(\mathsf{Cov}\left(U,X_{1}\right)=0\).
Crudu, Federico, Michael C. Knaus, Giovanni Mellace, and Joeri Smits. 2022. “On the Role of the Zero Conditional Mean Assumption for Causal Inference in Linear Models.” Working paper. Arxiv.
Hamermesh, Daniel S., and Amy Parker. 2005. “Beauty in the Classroom: Instructors’ Pulchritude and Putative Pedagogical Productivity.”Economics of Education Review 24 (4): 369–76.
Stock, James H., and Mark M. Watson. 2012. Introduction to Econometrics. Pearson.
We will have a chance to work with the full dataset later.↩︎
I say “typical” here because there are different types of datasets out there. For example, consider a selfie. That selfie could be represented as a dataset with a particular structure. Each pixel may have a numerical representation and the totality of all these pixels can be represented in a particular form which may be useful for further processing and analysis.↩︎
A Stata formatted dataset is not the most common format available, but it is used frequently in the social sciences. Text formatted datasets are usually more common. As a result, the built-in functions for loading datasets in R tend to focus more on text formatted datasets.↩︎
Where do these pieces of information come from? Typically, there would be documentation in the form of a codebook or a data dictionary.↩︎